 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOvercoming Catastrophic Forgetting by Soft Parameter Pruning
Paper and Code
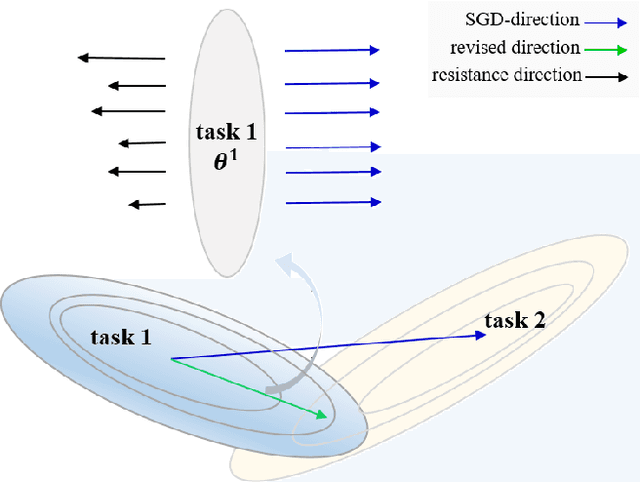

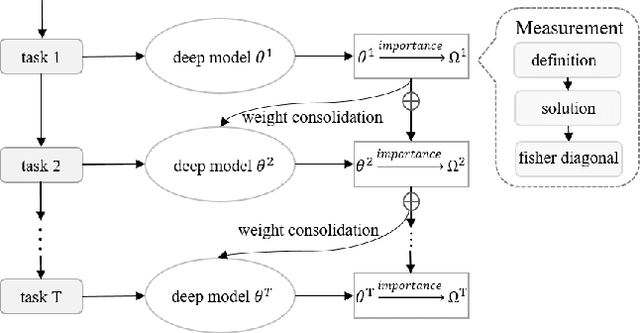
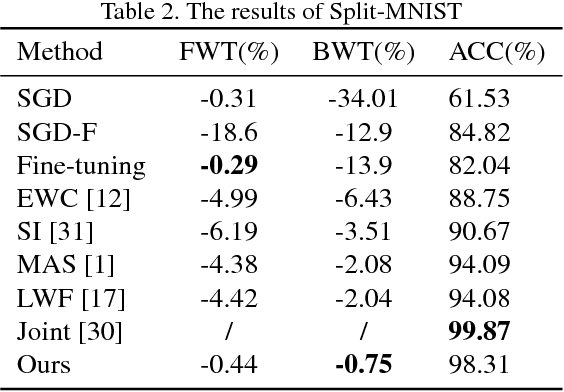
Catastrophic forgetting is a challenge issue in continual learning when a deep neural network forgets the knowledge acquired from the former task after learning on subsequent tasks. However, existing methods try to find the joint distribution of parameters shared with all tasks. This idea can be questionable because this joint distribution may not present when the number of tasks increase. On the other hand, It also leads to "long-term" memory issue when the network capacity is limited since adding tasks will "eat" the network capacity. In this paper, we proposed a Soft Parameters Pruning (SPP) strategy to reach the trade-off between short-term and long-term profit of a learning model by freeing those parameters less contributing to remember former task domain knowledge to learn future tasks, and preserving memories about previous tasks via those parameters effectively encoding knowledge about tasks at the same time. The SPP also measures the importance of parameters by information entropy in a label free manner. The experiments on several tasks shows SPP model achieved the best performance compared with others state-of-the-art methods. Experiment results also indicate that our method is less sensitive to hyper-parameter and better generalization. Our research suggests that a softer strategy, i.e. approximate optimize or sub-optimal solution, will benefit alleviating the dilemma of memory. The source codes are available at https://github.com/lehaifeng/Learning_by_memory.