 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Video Generation Using Action-Appearance Captions
Paper and Code
Dec 05, 2018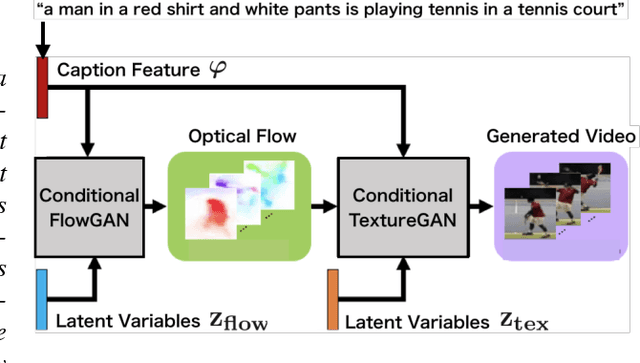

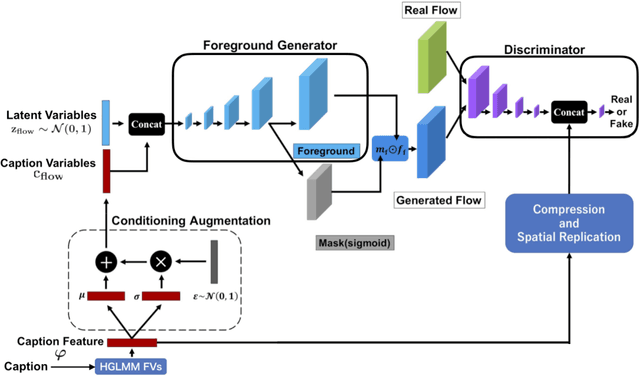

The field of automatic video generation has received a boost thanks to the recent Generative Adversarial Networks (GANs). However, most existing methods cannot control the contents of the generated video using a text caption, losing their usefulness to a large extent. This particularly affects human videos due to their great variety of actions and appearances. This paper presents Conditional Flow and Texture GAN (CFT-GAN), a GAN-based video generation method from action-appearance captions. We propose a novel way of generating video by encoding a caption (e.g., "a man in blue jeans is playing golf") in a two-stage generation pipeline. Our CFT-GAN uses such caption to generate an optical flow (action) and a texture (appearance) for each frame. As a result, the output video reflects the content specified in the caption in a plausible way. Moreover, to train our method, we constructed a new dataset for human video generation with captions. We evaluated the proposed method qualitatively and quantitatively via an ablation study and a user study. The results demonstrate that CFT-GAN is able to successfully generate videos containing the action and appearances indicated in the captions.