 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVADRA: Visual Adversarial Domain Randomization and Augmentation
Paper and Code
Dec 03, 2018

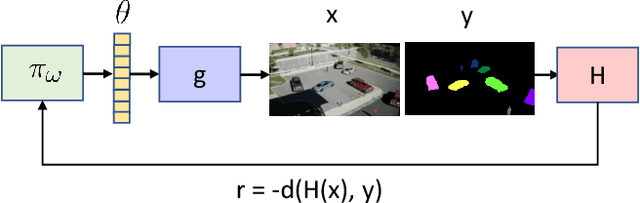

We address the issue of learning from synthetic domain randomized data effectively. While previous works have showcased domain randomization as an effective learning approach, it lacks in challenging the learner and wastes valuable compute on generating easy examples. This can be attributed to uniform randomization over the rendering parameter distribution. In this work, firstly we provide a theoretical perspective on characteristics of domain randomization and analyze its limitations. As a solution to these limitations, we propose a novel algorithm which closes the loop between the synthetic generative model and the learner in an adversarial fashion. Our framework easily extends to the scenario when there is unlabelled target data available, thus incorporating domain adaptation. We evaluate our method on diverse vision tasks using state-of-the-art simulators for public datasets like CLEVR, Syn2Real, and VIRAT, where we demonstrate that a learner trained using adversarial data generation performs better than using a random data generation strategy.