 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness Under Unawareness: Assessing Disparity When Protected Class Is Unobserved
Paper and Code
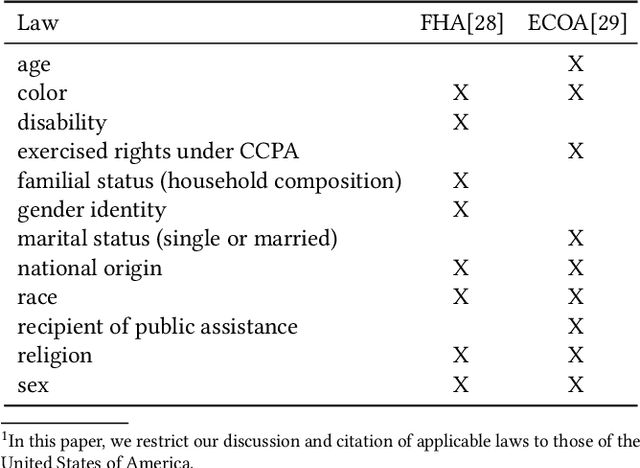
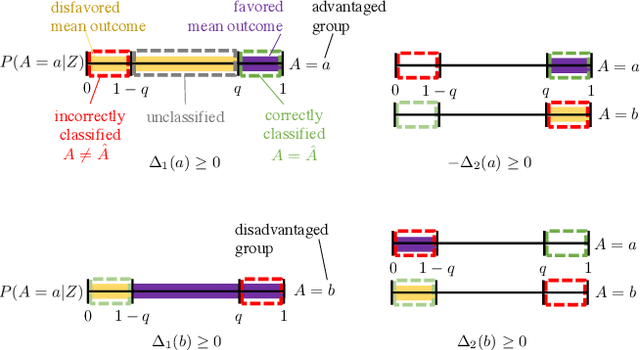

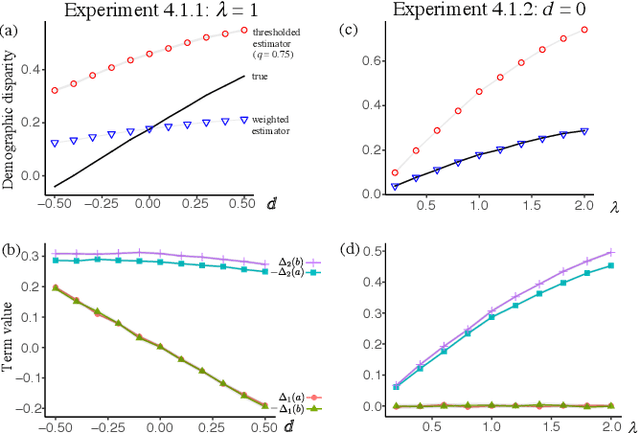
Assessing the fairness of a decision making system with respect to a protected class, such as gender or race, is challenging when class membership labels are unavailable. Probabilistic models for predicting the protected class based on observable proxies, such as surname and geolocation for race, are sometimes used to impute these missing labels for compliance assessments. Empirically, these methods are observed to exaggerate disparities, but the reason why is unknown. In this paper, we decompose the biases in estimating outcome disparity via threshold-based imputation into multiple interpretable bias sources, allowing us to explain when over- or underestimation occurs. We also propose an alternative weighted estimator that uses soft classification, and show that its bias arises simply from the conditional covariance of the outcome with the true class membership. Finally, we illustrate our results with numerical simulations and a public dataset of mortgage applications, using geolocation as a proxy for race. We confirm that the bias of threshold-based imputation is generally upward, but its magnitude varies strongly with the threshold chosen. Our new weighted estimator tends to have a negative bias that is much simpler to analyze and reason about.