 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicVO: End-to-End Monocular Visual Odometry through Deep Bi-directional Recurrent Convolutional Neural Network
Paper and Code
Nov 28, 2018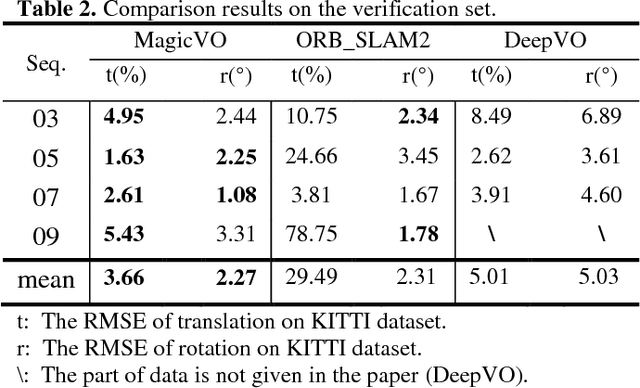
This paper proposes a new framework to solve the problem of monocular visual odometry, called MagicVO . Based on Convolutional Neural Network (CNN) and Bi-directional LSTM (Bi-LSTM), MagicVO outputs a 6-DoF absolute-scale pose at each position of the camera with a sequence of continuous monocular images as input. It not only utilizes the outstanding performance of CNN in image feature processing to extract the rich features of image frames fully but also learns the geometric relationship from image sequences pre and post through Bi-LSTM to get a more accurate prediction. A pipeline of the MagicVO is shown in Fig. 1. The MagicVO system is end-to-end, and the results of experiments on the KITTI dataset and the ETH-asl cla dataset show that MagicVO has a better performance than traditional visual odometry (VO) systems in the accuracy of pose and the generalization ability.