 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolarity Loss for Zero-shot Object Detection
Paper and Code
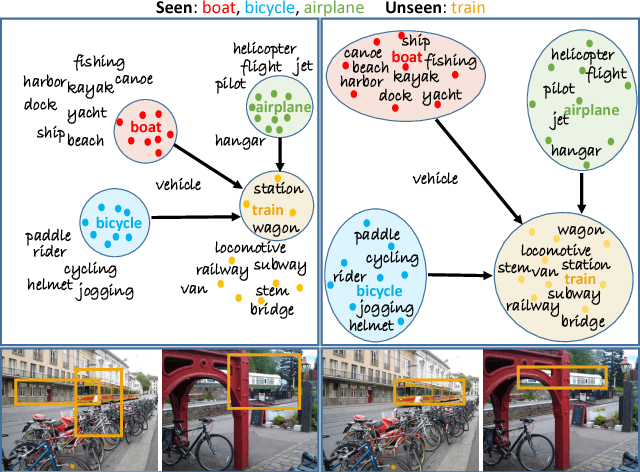
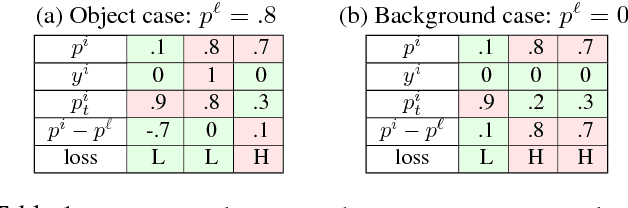
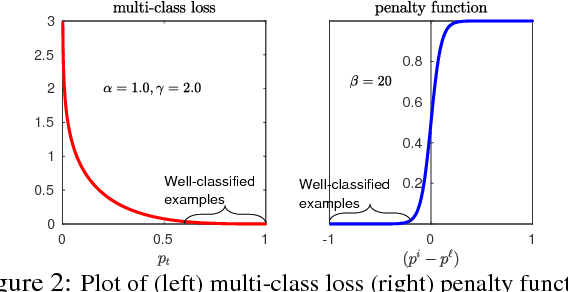
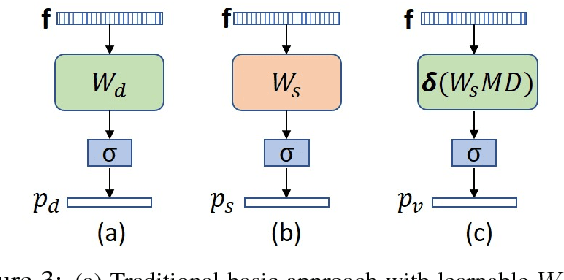
Zero-shot object detection is an emerging research topic that aims to recognize and localize previously 'unseen' objects. This setting gives rise to several unique challenges, e.g., highly imbalanced positive vs. negative instance ratio, ambiguity between background and unseen classes and the proper alignment between visual and semantic concepts. Here, we propose an end-to-end deep learning framework underpinned by a novel loss function that puts more emphasis on difficult examples to avoid class imbalance. We call our objective the 'Polarity loss' because it explicitly maximizes the gap between positive and negative predictions. Such a margin maximizing formulation is important as it improves the visual-semantic alignment while resolving the ambiguity between background and unseen. Our approach is inspired by the embodiment theories in cognitive science, that claim human semantic understanding to be grounded in past experiences (seen objects), related linguistic concepts (word dictionary) and the perception of the physical world (visual imagery). To this end, we learn to attend to a dictionary of related semantic concepts that eventually refines the noisy semantic embeddings and helps establish a better synergy between visual and semantic domains. Our extensive results on MS-COCO and Pascal VOC datasets show as high as 14 x mAP improvement over state of the art.