 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecognizing Disguised Faces in the Wild
Paper and Code
Nov 21, 2018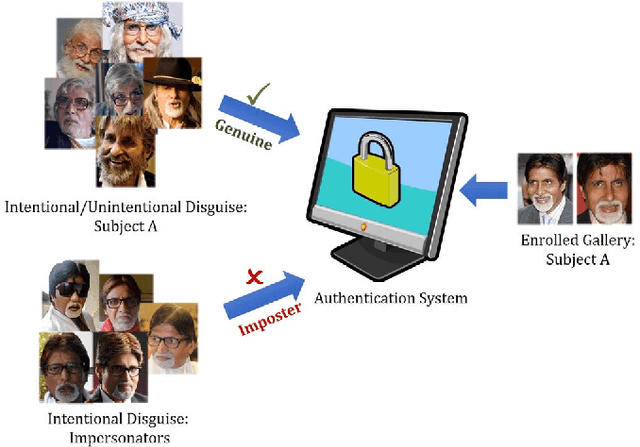

Research in face recognition has seen tremendous growth over the past couple of decades. Beginning from algorithms capable of performing recognition in constrained environments, the current face recognition systems achieve very high accuracies on large-scale unconstrained face datasets. While upcoming algorithms continue to achieve improved performance, a majority of the face recognition systems are susceptible to failure under disguise variations, one of the most challenging covariate of face recognition. Most of the existing disguise datasets contain images with limited variations, often captured in controlled settings. This does not simulate a real world scenario, where both intentional and unintentional unconstrained disguises are encountered by a face recognition system. In this paper, a novel Disguised Faces in the Wild (DFW) dataset is proposed which contains over 11000 images of 1000 identities with different types of disguise accessories. The dataset is collected from the Internet, resulting in unconstrained face images similar to real world settings. This is the first-of-a-kind dataset with the availability of impersonator and genuine obfuscated face images for each subject. The proposed dataset has been analyzed in terms of three levels of difficulty: (i) easy, (ii) medium, and (iii) hard in order to showcase the challenging nature of the problem. It is our view that the research community can greatly benefit from the DFW dataset in terms of developing algorithms robust to such adversaries. The proposed dataset was released as part of the First International Workshop and Competition on Disguised Faces in the Wild at CVPR, 2018. This paper presents the DFW dataset in detail, including the evaluation protocols, baseline results, performance analysis of the submissions received as part of the competition, and three levels of difficulties of the DFW challenge dataset.