 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Bayesian Dropout
Paper and Code
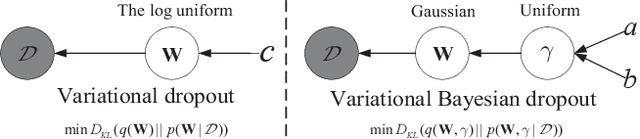
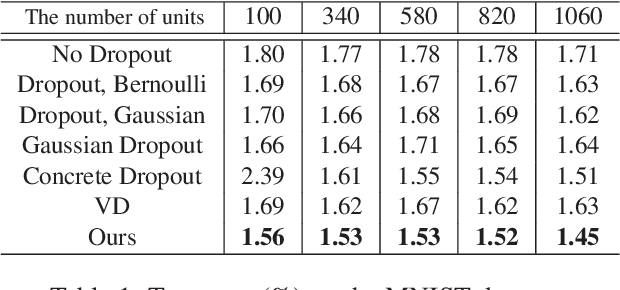
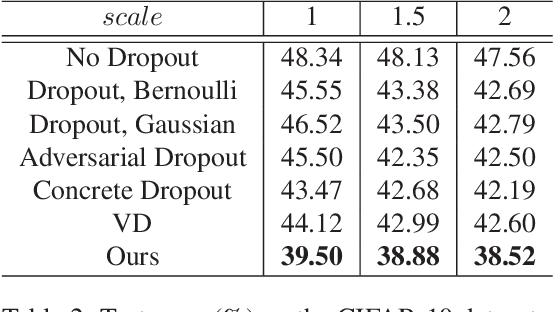
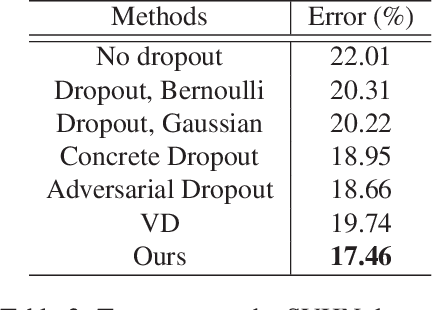
Variational dropout (VD) is a generalization of Gaussian dropout, which aims at inferring the posterior of network weights based on a log-uniform prior on them to learn these weights as well as dropout rate simultaneously. The log-uniform prior not only interprets the regularization capacity of Gaussian dropout in network training, but also underpins the inference of such posterior. However, the log-uniform prior is an improper prior (i.e., its integral is infinite) which causes the inference of posterior to be ill-posed, thus restricting the regularization performance of VD. To address this problem, we present a new generalization of Gaussian dropout, termed variational Bayesian dropout (VBD), which turns to exploit a hierarchical prior on the network weights and infer a new joint posterior. Specifically, we implement the hierarchical prior as a zero-mean Gaussian distribution with variance sampled from a uniform hyper-prior. Then, we incorporate such a prior into inferring the joint posterior over network weights and the variance in the hierarchical prior, with which both the network training and the dropout rate estimation can be cast into a joint optimization problem. More importantly, the hierarchical prior is a proper prior which enables the inference of posterior to be well-posed. In addition, we further show that the proposed VBD can be seamlessly applied to network compression. Experiments on both classification and network compression tasks demonstrate the superior performance of the proposed VBD in terms of regularizing network training.