 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Quality Prediction of Protein Q8 Secondary Structure by Diverse Neural Network Architectures
Paper and Code
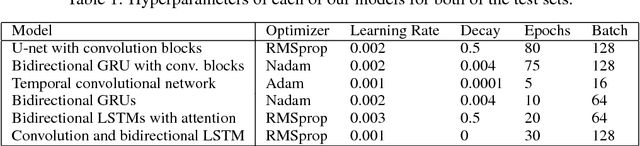
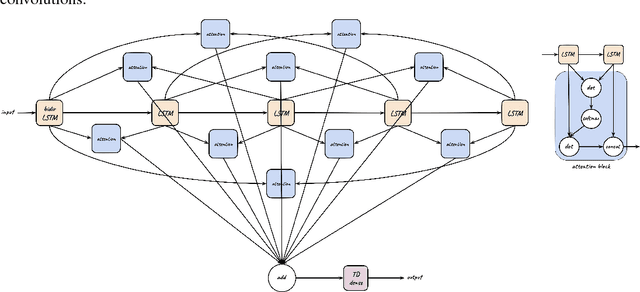
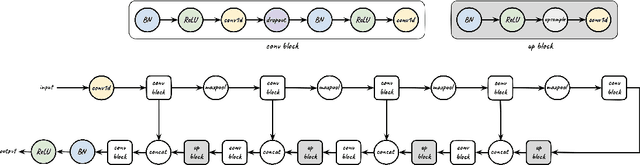
We tackle the problem of protein secondary structure prediction using a common task framework. This lead to the introduction of multiple ideas for neural architectures based on state of the art building blocks, used in this task for the first time. We take a principled machine learning approach, which provides genuine, unbiased performance measures, correcting longstanding errors in the application domain. We focus on the Q8 resolution of secondary structure, an active area for continuously improving methods. We use an ensemble of strong predictors to achieve accuracy of 70.7% (on the CB513 test set using the CB6133filtered training set). These results are statistically indistinguishable from those of the top existing predictors. In the spirit of reproducible research we make our data, models and code available, aiming to set a gold standard for purity of training and testing sets. Such good practices lower entry barriers to this domain and facilitate reproducible, extendable research.