 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Grammar Augmentation for Robust Voice Command Recognition
Paper and Code
Nov 14, 2018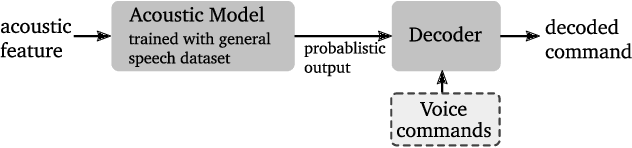


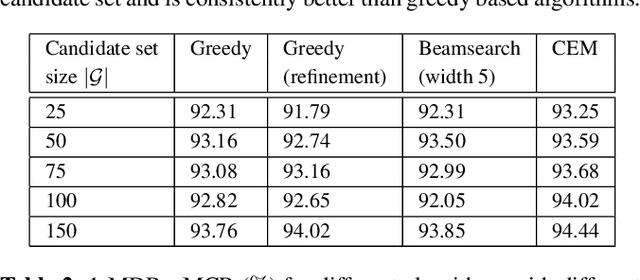
This paper proposes a novel pipeline for automatic grammar augmentation that provides a significant improvement in the voice command recognition accuracy for systems with small footprint acoustic model (AM). The improvement is achieved by augmenting the user-defined voice command set, also called grammar set, with alternate grammar expressions. For a given grammar set, a set of potential grammar expressions (candidate set) for augmentation is constructed from an AM-specific statistical pronunciation dictionary that captures the consistent patterns and errors in the decoding of AM induced by variations in pronunciation, pitch, tempo, accent, ambiguous spellings, and noise conditions. Using this candidate set, greedy optimization based and cross-entropy-method (CEM) based algorithms are considered to search for an augmented grammar set with improved recognition accuracy utilizing a command-specific dataset. Our experiments show that the proposed pipeline along with algorithms considered in this paper significantly reduce the mis-detection and mis-classification rate without increasing the false-alarm rate. Experiments also demonstrate the consistent superior performance of CEM method over greedy-based algorithms.