 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Environment Benchmarks for Reinforcement Learning
Paper and Code


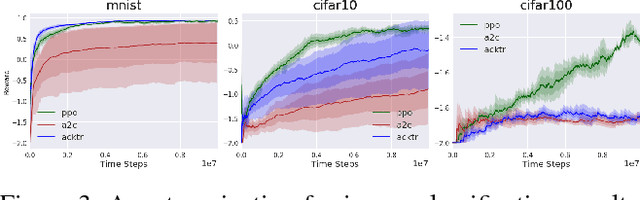
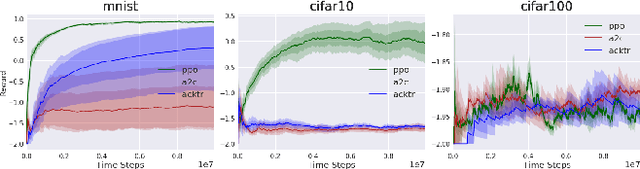
While current benchmark reinforcement learning (RL) tasks have been useful to drive progress in the field, they are in many ways poor substitutes for learning with real-world data. By testing increasingly complex RL algorithms on low-complexity simulation environments, we often end up with brittle RL policies that generalize poorly beyond the very specific domain. To combat this, we propose three new families of benchmark RL domains that contain some of the complexity of the natural world, while still supporting fast and extensive data acquisition. The proposed domains also permit a characterization of generalization through fair train/test separation, and easy comparison and replication of results. Through this work, we challenge the RL research community to develop more robust algorithms that meet high standards of evaluation.