 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Free Text to Clusters of Content in Health Records: An Unsupervised Graph Partitioning Approach
Paper and Code
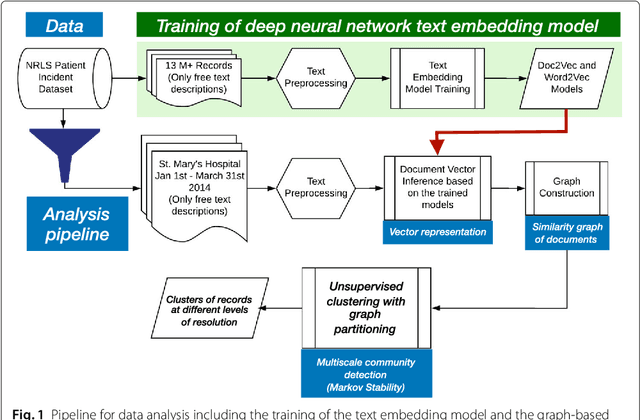
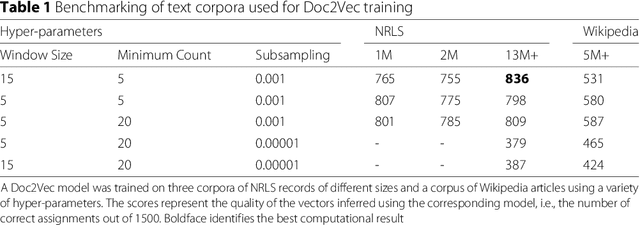
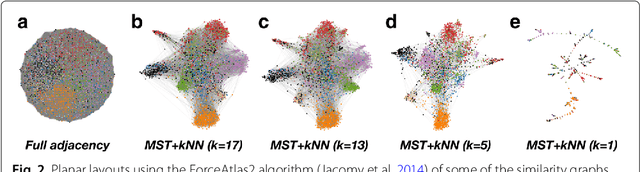
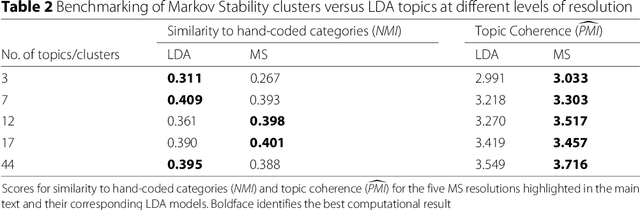
Electronic Healthcare records contain large volumes of unstructured data in different forms. Free text constitutes a large portion of such data, yet this source of richly detailed information often remains under-used in practice because of a lack of suitable methodologies to extract interpretable content in a timely manner. Here we apply network-theoretical tools to the analysis of free text in Hospital Patient Incident reports in the English National Health Service, to find clusters of reports in an unsupervised manner and at different levels of resolution based directly on the free text descriptions contained within them. To do so, we combine recently developed deep neural network text-embedding methodologies based on paragraph vectors with multi-scale Markov Stability community detection applied to a similarity graph of documents obtained from sparsified text vector similarities. We showcase the approach with the analysis of incident reports submitted in Imperial College Healthcare NHS Trust, London. The multiscale community structure reveals levels of meaning with different resolution in the topics of the dataset, as shown by relevant descriptive terms extracted from the groups of records, as well as by comparing a posteriori against hand-coded categories assigned by healthcare personnel. Our content communities exhibit good correspondence with well-defined hand-coded categories, yet our results also provide further medical detail in certain areas as well as revealing complementary descriptors of incidents beyond the external classification. We also discuss how the method can be used to monitor reports over time and across different healthcare providers, and to detect emerging trends that fall outside of pre-existing categories.