 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeteroscedastic Bandits with Reneging
Paper and Code
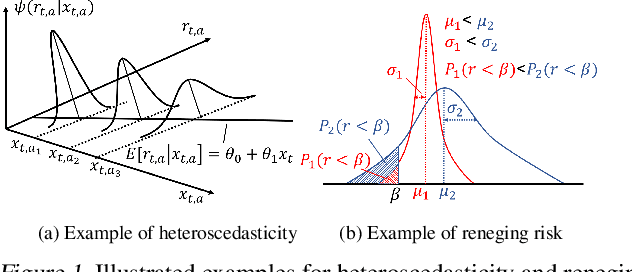
Although shown to be useful in many areas as models for solving sequential decision problems with side observations (contexts), contextual bandits are subject to two major limitations. First, they neglect user "reneging" that occurs in real-world applications. That is, users unsatisfied with an interaction quit future interactions forever. Second, they assume that the reward distribution is homoscedastic, which is often invalidated by real-world datasets, e.g., datasets from finance. We propose a novel model of "heteroscedastic contextual bandits with reneging" to overcome the two limitations. Our model allows each user to have a distinct "acceptance level," with any interaction falling short of that level resulting in that user reneging. It also allows the variance to be a function of context. We develop a UCB-type of policy, called HR-UCB, and prove that with high probability it achieves $\mathcal{O}\Big(\sqrt{{T}}\big(\log({T})\big)^{3/2}\Big)$ regret.