 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic representation: finding more representative words in topic models
Paper and Code
Oct 23, 2018
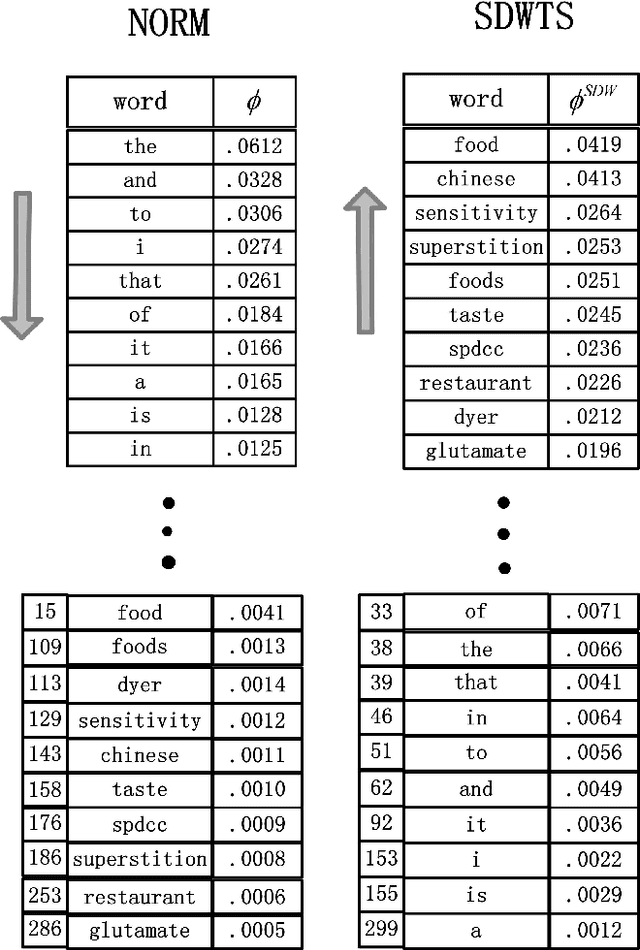

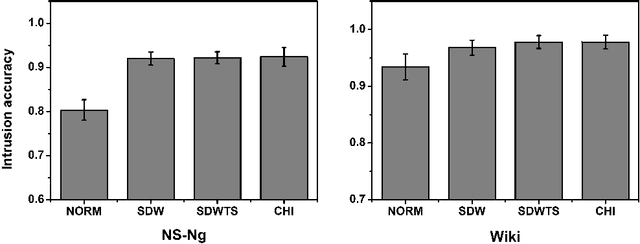
The top word list, i.e., the top-M words with highest marginal probability in a given topic, is the standard topic representation in topic models. Most of recent automatical topic labeling algorithms and popular topic quality metrics are based on it. However, we find, empirically, words in this type of top word list are not always representative. The objective of this paper is to find more representative top word lists for topics. To achieve this, we rerank the words in a given topic by further considering marginal probability on words over every other topic. The reranking list of top-M words is used to be a novel topic representation for topic models. We investigate three reranking methodologies, using (1) standard deviation weight, (2) standard deviation weight with topic size and (3) Chi Square \c{hi}2statistic selection. Experimental results on real world collections indicate that our representations can extract more representative words for topics, agreeing with human judgements.