 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned optimizers that outperform SGD on wall-clock and test loss
Paper and Code
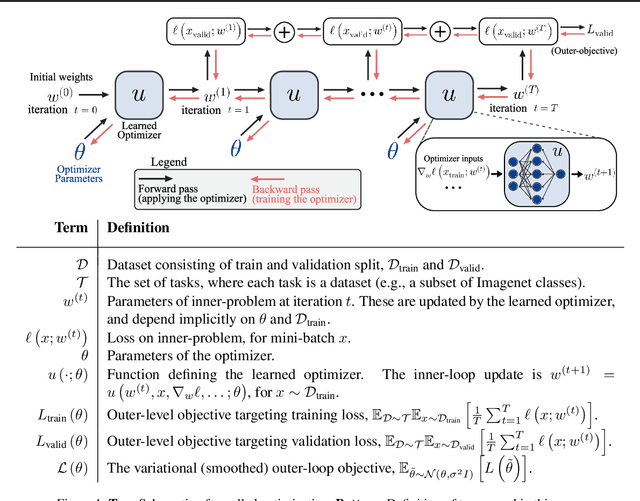
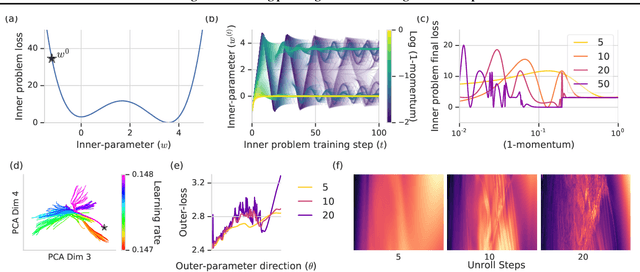
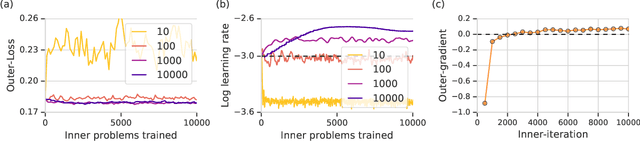
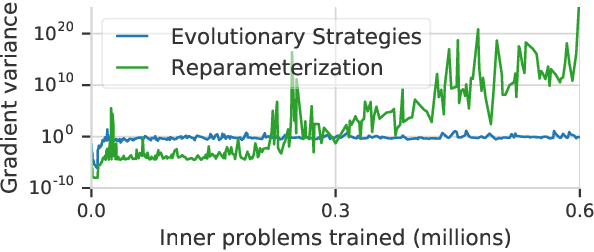
Deep learning has shown that learned functions can dramatically outperform hand-designed functions on perceptual tasks. Analogously, this suggests that learned optimizers may similarly outperform current hand-designed optimizers, especially for specific problems. However, learned optimizers are notoriously difficult to train and have yet to demonstrate wall-clock speedups over hand-designed optimizers, and thus are rarely used in practice. Typically, learned optimizers are trained by truncated backpropagation through an unrolled optimization process. The resulting gradients are either strongly biased (for short truncations) or have exploding norm (for long truncations). In this work we propose a training scheme which overcomes both of these difficulties, by dynamically weighting two unbiased gradient estimators for a variational loss on optimizer performance. This allows us to train neural networks to perform optimization of a specific task faster than well tuned first-order methods. Moreover, by training the optimizer against validation loss (as opposed to training loss), we are able to learn optimizers that train networks to better generalization than first order methods. We demonstrate these results on problems where our learned optimizer trains convolutional networks in a fifth of the wall-clock time compared to tuned first-order methods, and with an improvement in test loss.