 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA jamming transition from under- to over-parametrization affects loss landscape and generalization
Paper and Code
Oct 22, 2018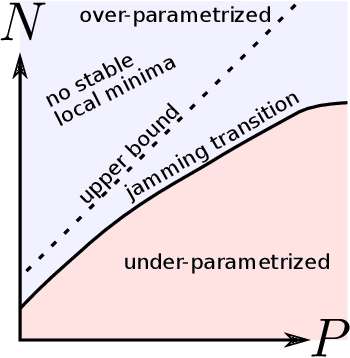
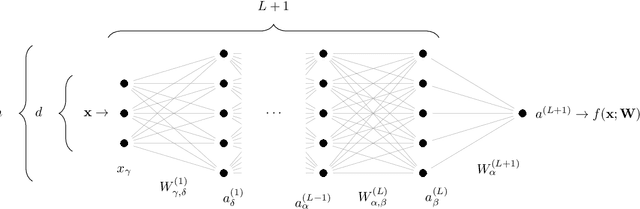
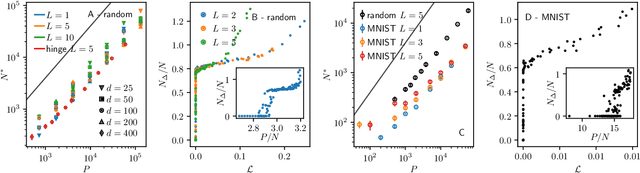
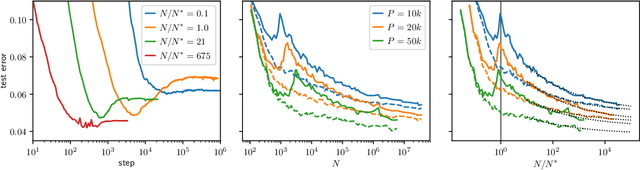
We argue that in fully-connected networks a phase transition delimits the over- and under-parametrized regimes where fitting can or cannot be achieved. Under some general conditions, we show that this transition is sharp for the hinge loss. In the whole over-parametrized regime, poor minima of the loss are not encountered during training since the number of constraints to satisfy is too small to hamper minimization. Our findings support a link between this transition and the generalization properties of the network: as we increase the number of parameters of a given model, starting from an under-parametrized network, we observe that the generalization error displays three phases: (i) initial decay, (ii) increase until the transition point --- where it displays a cusp --- and (iii) power law decay toward a constant for the rest of the over-parametrized regime. Thereby we identify the region where the classical phenomenon of over-fitting takes place, and the region where the model keeps improving, in line with previous empirical observations for modern neural networks. The theoretical results presented here appeared elsewhere for a physics audience. The results on generalization are new.