 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multilingual Semantic Textual Similarity with Shared Sentence Encoder for Low-resource Languages
Paper and Code
Oct 30, 2018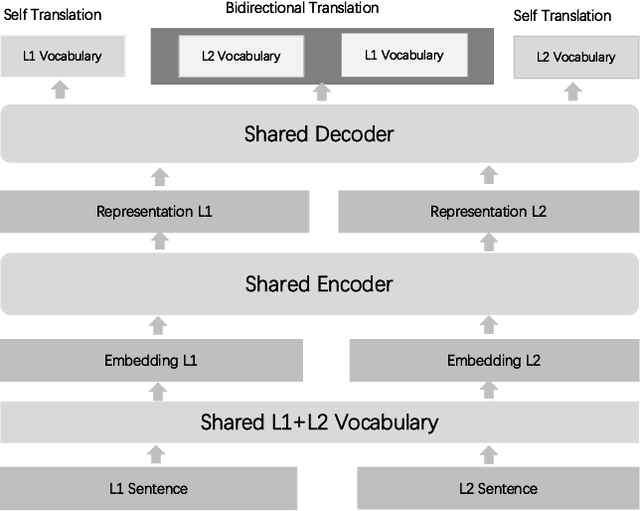
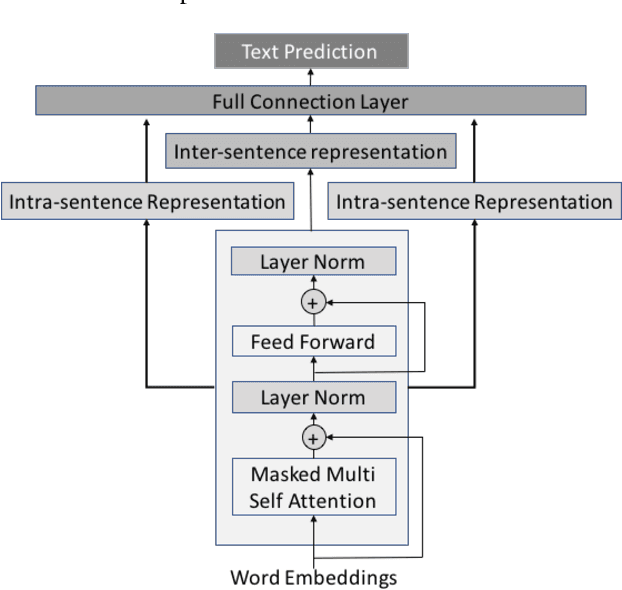

Measuring the semantic similarity between two sentences (or Semantic Textual Similarity - STS) is fundamental in many NLP applications. Despite the remarkable results in supervised settings with adequate labeling, little attention has been paid to this task in low-resource languages with insufficient labeling. Existing approaches mostly leverage machine translation techniques to translate sentences into rich-resource language. These approaches either beget language biases, or be impractical in industrial applications where spoken language scenario is more often and rigorous efficiency is required. In this work, we propose a multilingual framework to tackle the STS task in a low-resource language e.g. Spanish, Arabic , Indonesian and Thai, by utilizing the rich annotation data in a rich resource language, e.g. English. Our approach is extended from a basic monolingual STS framework to a shared multilingual encoder pretrained with translation task to incorporate rich-resource language data. By exploiting the nature of a shared multilingual encoder, one sentence can have multiple representations for different target translation language, which are used in an ensemble model to improve similarity evaluation. We demonstrate the superiority of our method over other state of the art approaches on SemEval STS task by its significant improvement on non-MT method, as well as an online industrial product where MT method fails to beat baseline while our approach still has consistently improvements.