 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassively Parallel Hyperparameter Tuning
Paper and Code
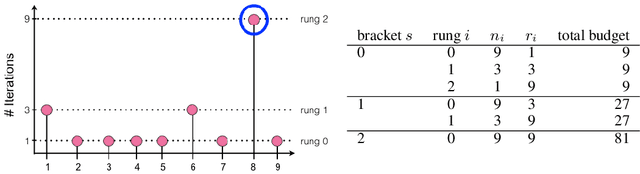

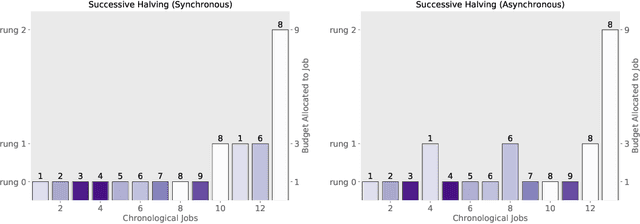
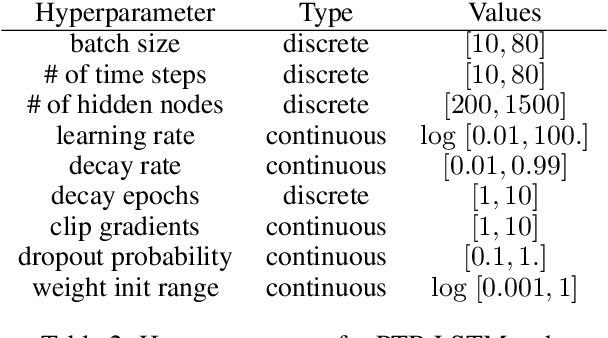
Modern learning models are characterized by large hyperparameter spaces. In order to adequately explore these large spaces, we must evaluate a large number of configurations, typically orders of magnitude more configurations than available parallel workers. Given the growing costs of model training, we would ideally like to perform this search in roughly the same wall-clock time needed to train a single model. In this work, we tackle this challenge by introducing ASHA, a simple and robust hyperparameter tuning algorithm with solid theoretical underpinnings that exploits parallelism and aggressive early-stopping. Our extensive empirical results show that ASHA slightly outperforms Fabolas and Population Based Tuning, state-of-the hyperparameter tuning methods; scales linearly with the number of workers in distributed settings; converges to a high quality configuration in half the time taken by Vizier (Google's internal hyperparameter tuning service) in an experiment with 500 workers; and beats the published result for a near state-of-the-art LSTM architecture in under 2x the time to train a single model.