 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D Human Body Correspondences from Panoramic Depth Maps
Paper and Code
Oct 12, 2018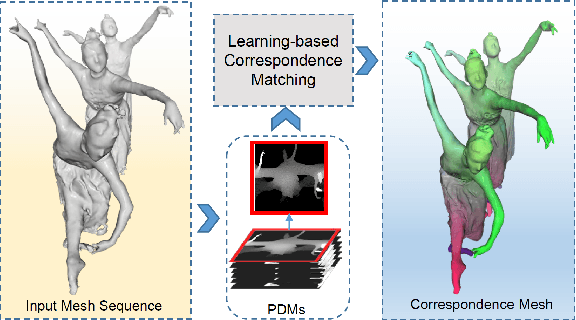
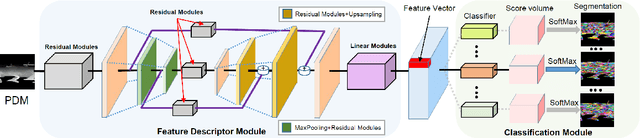
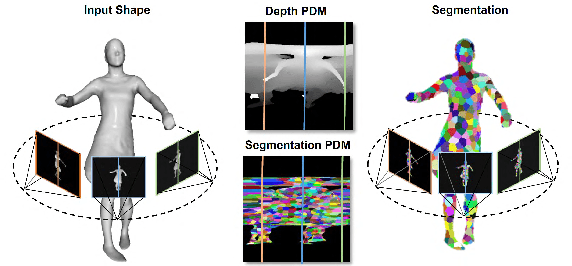
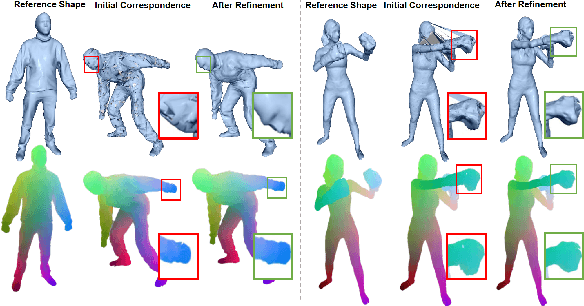
The availability of affordable 3D full body reconstruction systems has given rise to free-viewpoint video (FVV) of human shapes. Most existing solutions produce temporally uncorrelated point clouds or meshes with unknown point/vertex correspondences. Individually compressing each frame is ineffective and still yields to ultra-large data sizes. We present an end-to-end deep learning scheme to establish dense shape correspondences and subsequently compress the data. Our approach uses sparse set of "panoramic" depth maps or PDMs, each emulating an inward-viewing concentric mosaics. We then develop a learning-based technique to learn pixel-wise feature descriptors on PDMs. The results are fed into an autoencoder-based network for compression. Comprehensive experiments demonstrate our solution is robust and effective on both public and our newly captured datasets.