 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Winograd Convolutional neural networks on small-scale systolic arrays
Paper and Code
Oct 03, 2018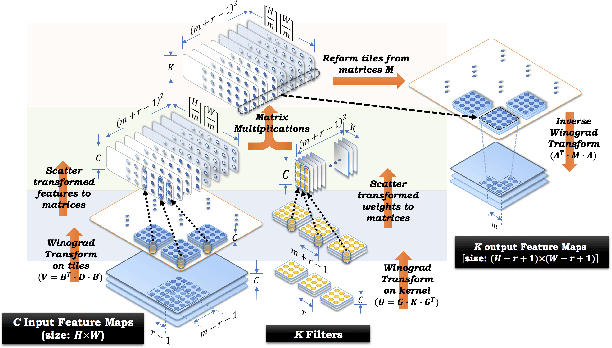
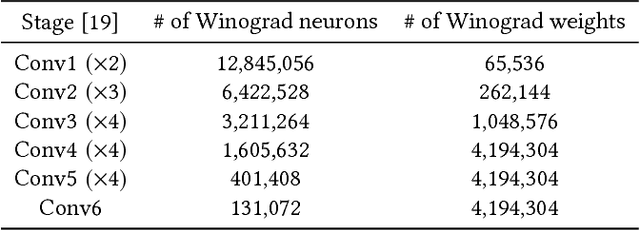
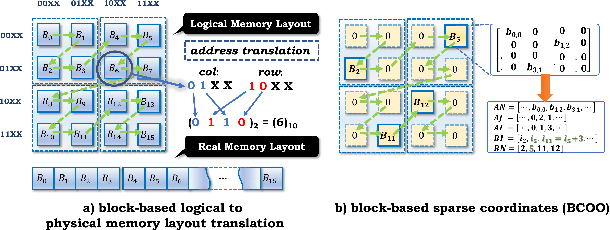
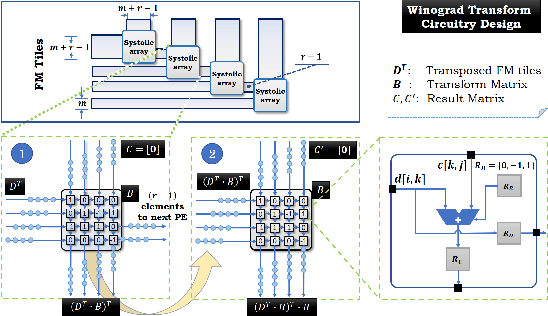
The reconfigurability, energy-efficiency, and massive parallelism on FPGAs make them one of the best choices for implementing efficient deep learning accelerators. However, state-of-art implementations seldom consider the balance between high throughput of computation power and the ability of the memory subsystem to support it. In this paper, we implement an accelerator on FPGA by combining the sparse Winograd convolution, clusters of small-scale systolic arrays, and a tailored memory layout design. We also provide an analytical model analysis for the general Winograd convolution algorithm as a design reference. Experimental results on VGG16 show that it achieves very high computational resource utilization, 20x ~ 30x energy efficiency, and more than 5x speedup compared with the dense implementation.