 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalar Arithmetic Multiple Data: Customizable Precision for Deep Neural Networks
Paper and Code
Sep 27, 2018

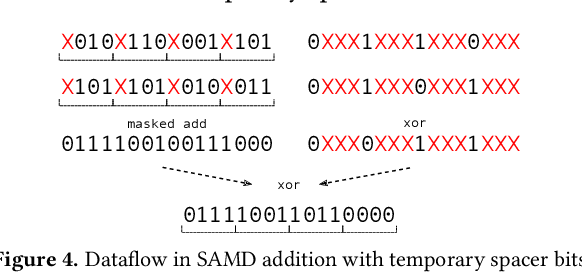

Quantization of weights and activations in Deep Neural Networks (DNNs) is a powerful technique for network compression, and has enjoyed significant attention and success. However, much of the inference-time benefit of quantization is accessible only through the use of customized hardware accelerators or by providing an FPGA implementation of quantized arithmetic. Building on prior work, we show how to construct arbitrary bit-precise signed and unsigned integer operations using a software technique which logically \emph{embeds} a vector architecture with custom bit-width lanes in universally available fixed-width scalar arithmetic. We evaluate our approach on a high-end Intel Haswell processor, and an embedded ARM processor. Our approach yields very fast implementations of bit-precise custom DNN operations, which often match or exceed the performance of operations quantized to the sizes supported in native arithmetic. At the strongest level of quantization, our approach yields a maximum speedup of $\thicksim6\times$ on the Intel platform, and $\thicksim10\times$ on the ARM platform versus quantization to native 8-bit integers.