 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Neural Text Classification
Paper and Code
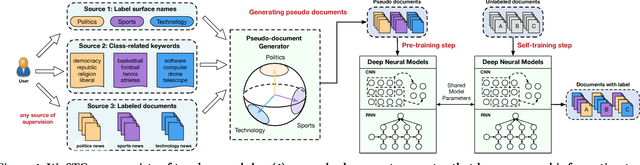

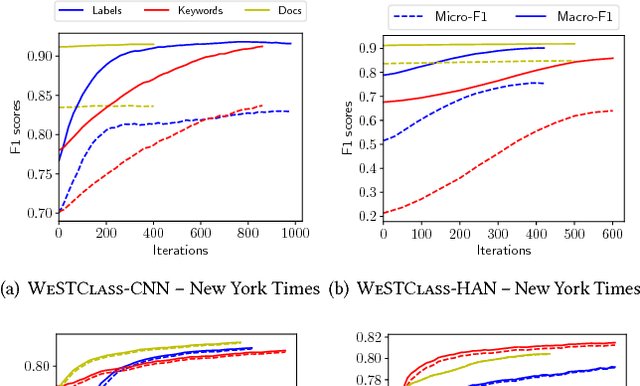
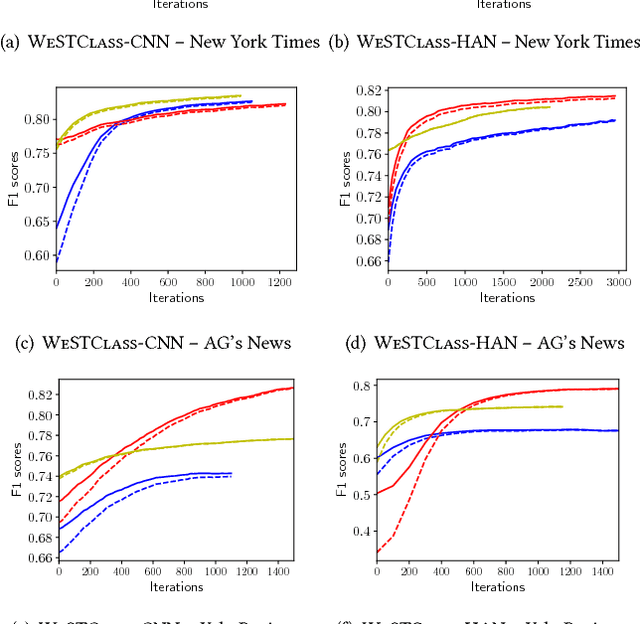
Deep neural networks are gaining increasing popularity for the classic text classification task, due to their strong expressive power and less requirement for feature engineering. Despite such attractiveness, neural text classification models suffer from the lack of training data in many real-world applications. Although many semi-supervised and weakly-supervised text classification models exist, they cannot be easily applied to deep neural models and meanwhile support limited supervision types. In this paper, we propose a weakly-supervised method that addresses the lack of training data in neural text classification. Our method consists of two modules: (1) a pseudo-document generator that leverages seed information to generate pseudo-labeled documents for model pre-training, and (2) a self-training module that bootstraps on real unlabeled data for model refinement. Our method has the flexibility to handle different types of weak supervision and can be easily integrated into existing deep neural models for text classification. We have performed extensive experiments on three real-world datasets from different domains. The results demonstrate that our proposed method achieves inspiring performance without requiring excessive training data and outperforms baseline methods significantly.