 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally Coherent Video Harmonization Using Adversarial Networks
Paper and Code
Sep 05, 2018
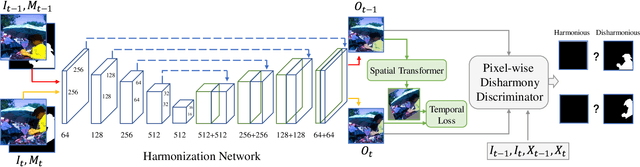


Compositing is one of the most important editing operations for images and videos. The process of improving the realism of composite results is often called harmonization. Previous approaches for harmonization mainly focus on images. In this work, we take one step further to attack the problem of video harmonization. Specifically, we train a convolutional neural network in an adversarial way, exploiting a pixel-wise disharmony discriminator to achieve more realistic harmonized results and introducing a temporal loss to increase temporal consistency between consecutive harmonized frames. Thanks to the pixel-wise disharmony discriminator, we are also able to relieve the need of input foreground masks. Since existing video datasets which have ground-truth foreground masks and optical flows are not sufficiently large, we propose a simple yet efficient method to build up a synthetic dataset supporting supervised training of the proposed adversarial network. Experiments show that training on our synthetic dataset generalizes well to the real-world composite dataset. Also, our method successfully incorporates temporal consistency during training and achieves more harmonious results than previous methods.