 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmergence of Communication in an Interactive World with Consistent Speakers
Paper and Code
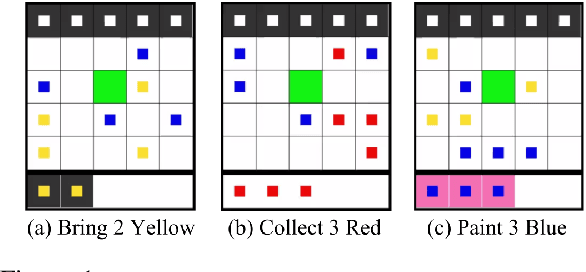
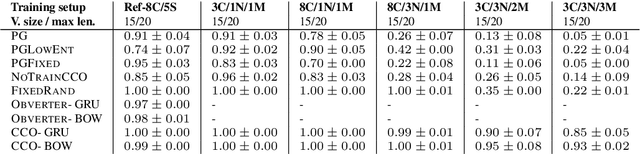
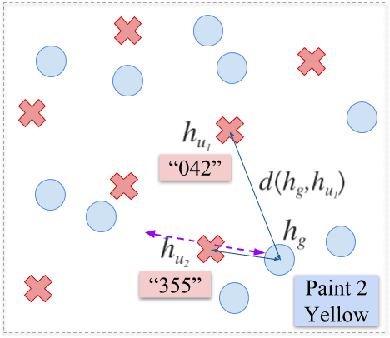
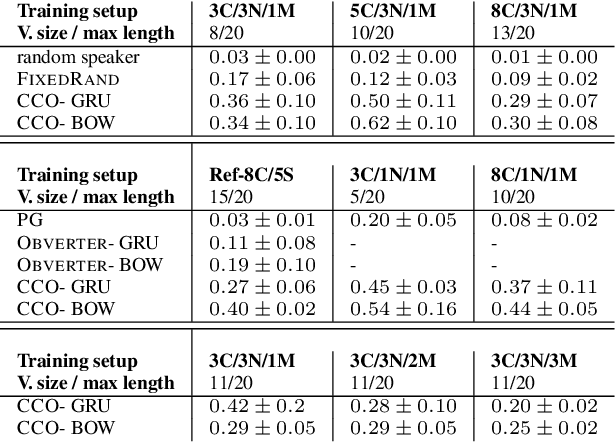
Training agents to communicate with one another given task-based supervision only has attracted considerable attention recently, due to the growing interest in developing models for human-agent interaction. Prior work on the topic focused on simple environments, where training using policy gradient was feasible despite the non-stationarity of the agents during training. In this paper, we present a more challenging environment for testing the emergence of communication from raw pixels, where training using policy gradient fails. We propose a new model and training algorithm, that utilizes the structure of a learned representation space to produce more consistent speakers at the initial phases of training, which stabilizes learning. We empirically show that our algorithm substantially improves performance compared to policy gradient. We also propose a new alignment-based metric for measuring context-independence in emerged communication and find our method increases context-independence compared to policy gradient and other competitive baselines.