 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Semantic-Aware Network Embedding with Fine-Grained Word Alignment
Paper and Code
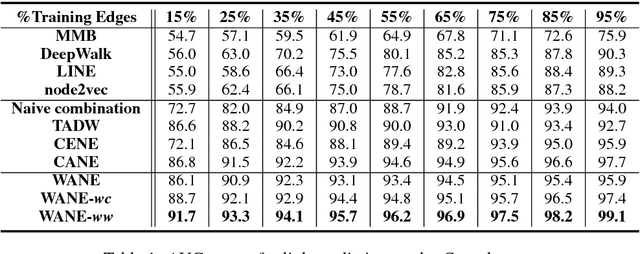
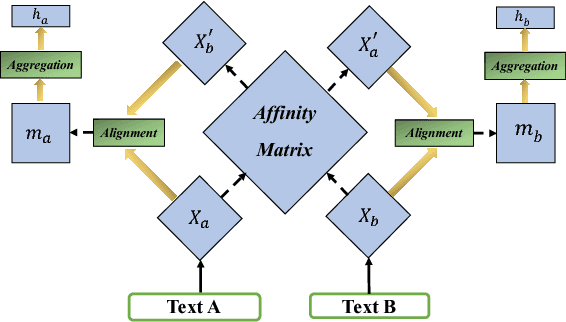
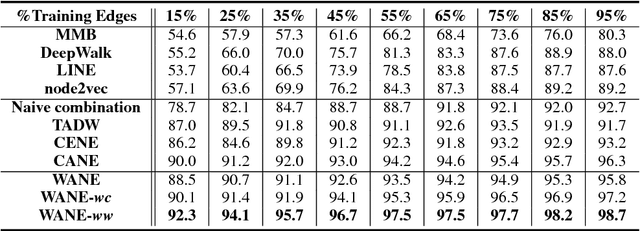
Network embeddings, which learn low-dimensional representations for each vertex in a large-scale network, have received considerable attention in recent years. For a wide range of applications, vertices in a network are typically accompanied by rich textual information such as user profiles, paper abstracts, etc. We propose to incorporate semantic features into network embeddings by matching important words between text sequences for all pairs of vertices. We introduce a word-by-word alignment framework that measures the compatibility of embeddings between word pairs, and then adaptively accumulates these alignment features with a simple yet effective aggregation function. In experiments, we evaluate the proposed framework on three real-world benchmarks for downstream tasks, including link prediction and multi-label vertex classification. Results demonstrate that our model outperforms state-of-the-art network embedding methods by a large margin.