 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel and Sample: Efficient Training of Vehicle Object Detector from Sparsely Labeled Data
Paper and Code
Aug 26, 2018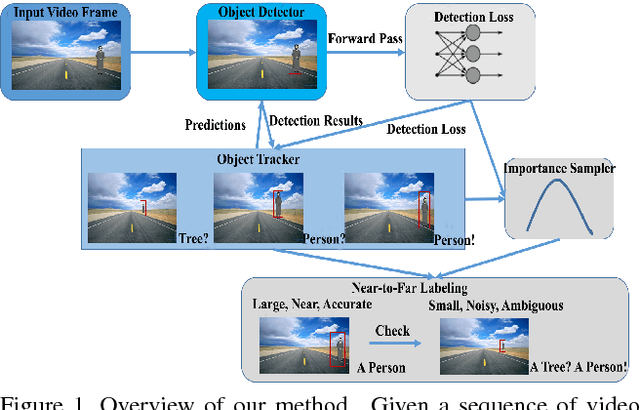
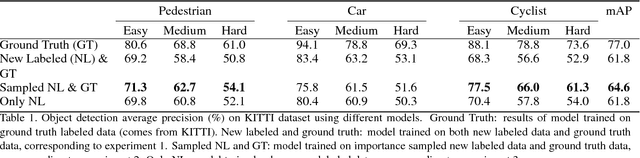

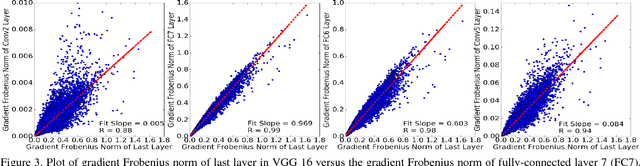
Self-driving vehicle vision systems must deal with an extremely broad and challenging set of scenes. They can potentially exploit an enormous amount of training data collected from vehicles in the field, but the volumes are too large to train offline naively. Not all training instances are equally valuable though, and importance sampling can be used to prioritize which training images to collect. This approach assumes that objects in images are labeled with high accuracy. To generate accurate labels in the field, we exploit the spatio-temporal coherence of vehicle video. We use a near-to-far labeling strategy by first labeling large, close objects in the video, and tracking them back in time to induce labels on small distant presentations of those objects. In this paper we demonstrate the feasibility of this approach in several steps. First, we note that an optimal subset (relative to all the objects encountered and labeled) of labeled objects in images can be obtained by importance sampling using gradients of the recognition network. Next we show that these gradients can be approximated with very low error using the loss function, which is already available when the CNN is running inference. Then, we generalize these results to objects in a larger scene using an object detection system. Finally, we describe a self-labeling scheme using object tracking. Objects are tracked back in time (near-to-far) and labels of near objects are used to check accuracy of those objects in the far field. We then evaluate the accuracy of models trained on importance sampled data vs models trained on complete data.