 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOverview of the CLEF-2018 CheckThat! Lab on Automatic Identification and Verification of Political Claims. Task 1: Check-Worthiness
Paper and Code
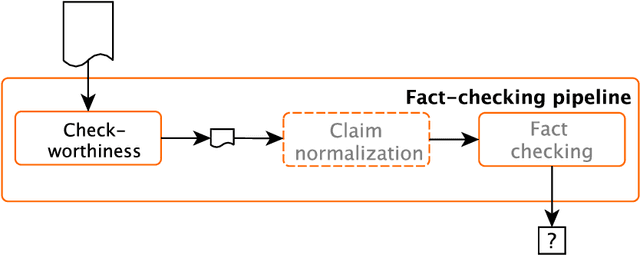
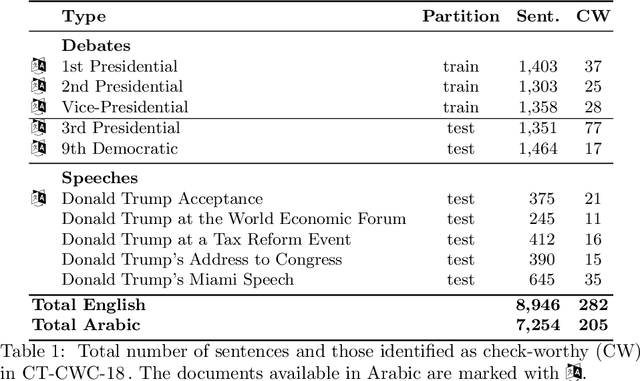

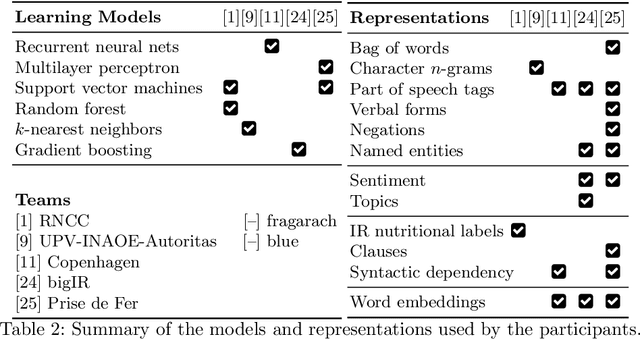
We present an overview of the CLEF-2018 CheckThat! Lab on Automatic Identification and Verification of Political Claims, with focus on Task 1: Check-Worthiness. The task asks to predict which claims in a political debate should be prioritized for fact-checking. In particular, given a debate or a political speech, the goal was to produce a ranked list of its sentences based on their worthiness for fact checking. We offered the task in both English and Arabic, based on debates from the 2016 US Presidential Campaign, as well as on some speeches during and after the campaign. A total of 30 teams registered to participate in the Lab and seven teams actually submitted systems for Task~1. The most successful approaches used by the participants relied on recurrent and multi-layer neural networks, as well as on combinations of distributional representations, on matchings claims' vocabulary against lexicons, and on measures of syntactic dependency. The best systems achieved mean average precision of 0.18 and 0.15 on the English and on the Arabic test datasets, respectively. This leaves large room for further improvement, and thus we release all datasets and the scoring scripts, which should enable further research in check-worthiness estimation.