 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetically Trained Icon Proposals for Parsing and Summarizing Infographics
Paper and Code
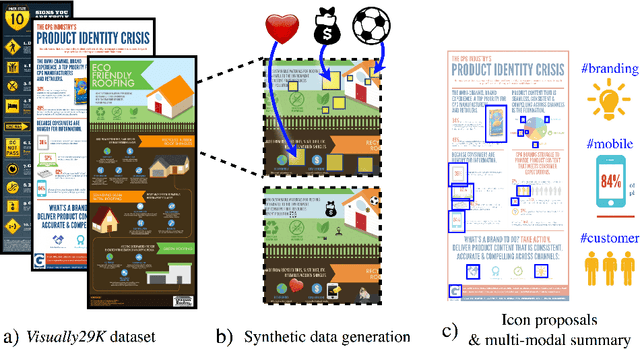
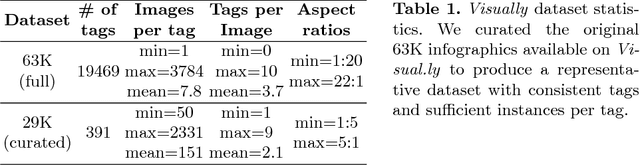

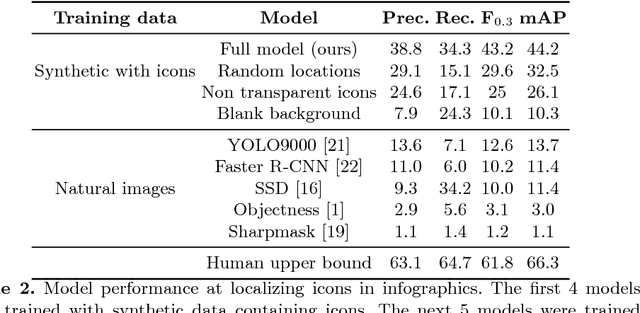
Widely used in news, business, and educational media, infographics are handcrafted to effectively communicate messages about complex and often abstract topics including `ways to conserve the environment' and `understanding the financial crisis'. Composed of stylistically and semantically diverse visual and textual elements, infographics pose new challenges for computer vision. While automatic text extraction works well on infographics, computer vision approaches trained on natural images fail to identify the stand-alone visual elements in infographics, or `icons'. To bridge this representation gap, we propose a synthetic data generation strategy: we augment background patches in infographics from our Visually29K dataset with Internet-scraped icons which we use as training data for an icon proposal mechanism. On a test set of 1K annotated infographics, icons are located with 38% precision and 34% recall (the best model trained with natural images achieves 14% precision and 7% recall). Combining our icon proposals with icon classification and text extraction, we present a multi-modal summarization application. Our application takes an infographic as input and automatically produces text tags and visual hashtags that are textually and visually representative of the infographic's topics respectively.