 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVDepthNet: Real-time Multiview Depth Estimation Neural Network
Paper and Code
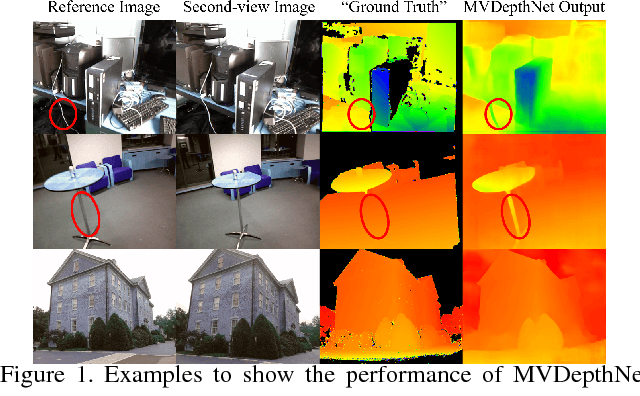
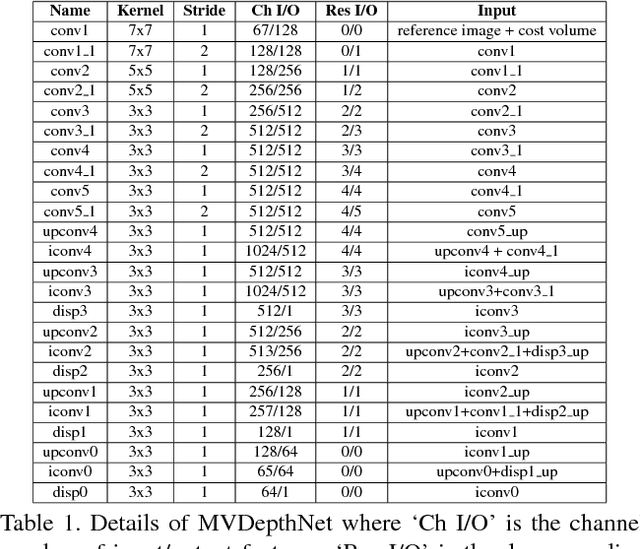
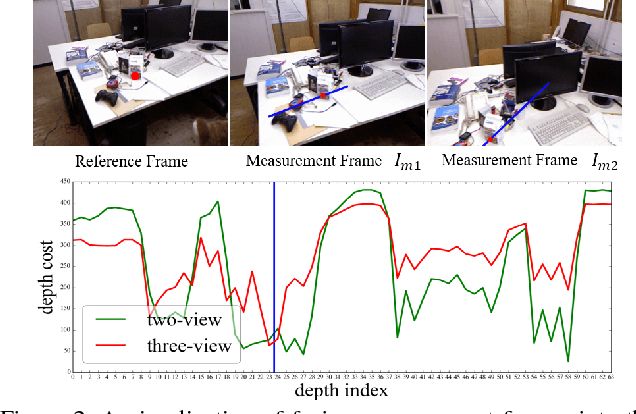
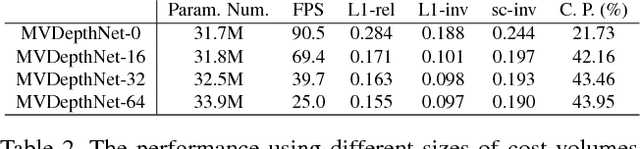
Although deep neural networks have been widely applied to computer vision problems, extending them into multiview depth estimation is non-trivial. In this paper, we present MVDepthNet, a convolutional network to solve the depth estimation problem given several image-pose pairs from a localized monocular camera in neighbor viewpoints. Multiview observations are encoded in a cost volume and then combined with the reference image to estimate the depth map using an encoder-decoder network. By encoding the information from multiview observations into the cost volume, our method achieves real-time performance and the flexibility of traditional methods that can be applied regardless of the camera intrinsic parameters and the number of images. Geometric data augmentation is used to train MVDepthNet. We further apply MVDepthNet in a monocular dense mapping system that continuously estimates depth maps using a single localized moving camera. Experiments show that our method can generate depth maps efficiently and precisely.