 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Reconstruction from Model Explanations
Paper and Code
Jul 13, 2018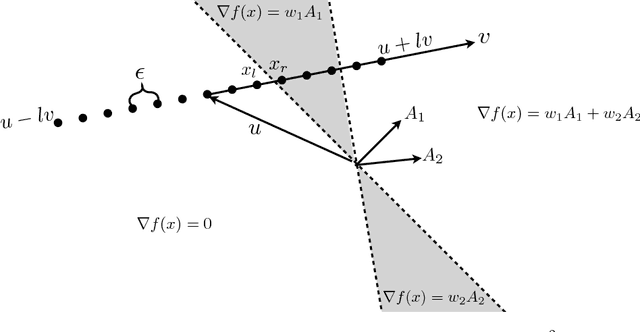
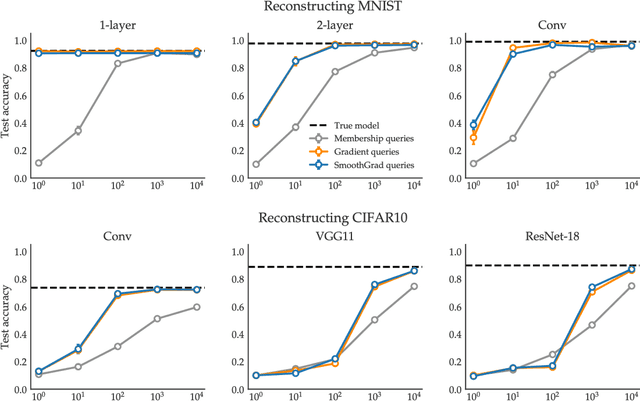
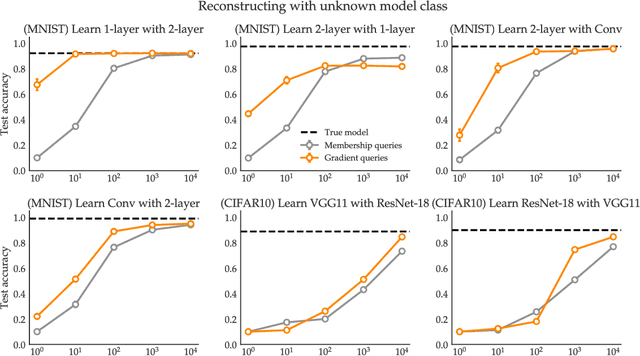
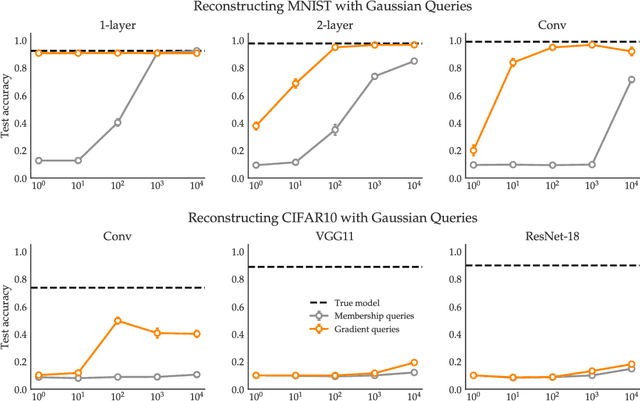
We show through theory and experiment that gradient-based explanations of a model quickly reveal the model itself. Our results speak to a tension between the desire to keep a proprietary model secret and the ability to offer model explanations. On the theoretical side, we give an algorithm that provably learns a two-layer ReLU network in a setting where the algorithm may query the gradient of the model with respect to chosen inputs. The number of queries is independent of the dimension and nearly optimal in its dependence on the model size. Of interest not only from a learning-theoretic perspective, this result highlights the power of gradients rather than labels as a learning primitive. Complementing our theory, we give effective heuristics for reconstructing models from gradient explanations that are orders of magnitude more query-efficient than reconstruction attacks relying on prediction interfaces.