 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning models for visual 3D localization with implicit mapping
Paper and Code
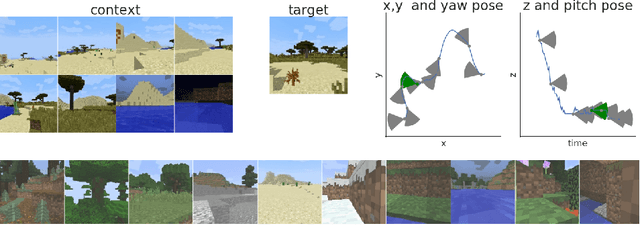
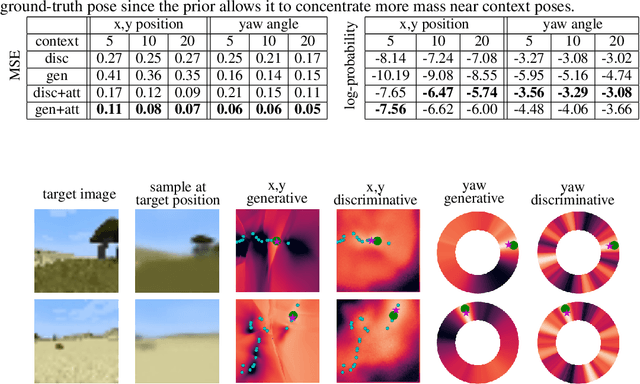
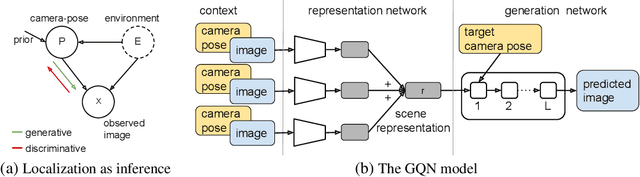
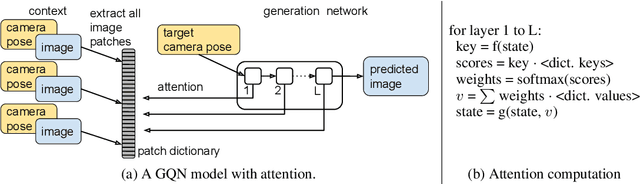
We propose a formulation of visual localization that does not require construction of explicit maps in the form of point clouds or voxels. The goal is to learn an implicit representation of the environment at a higher, more abstract level, for instance that of objects. To study this approach we consider procedurally generated Minecraft worlds, for which we can generate visually rich images along with camera pose coordinates. We first show that Generative Query Networks (GQNs) enhanced with a novel attention mechanism can capture the visual structure of 3D scenes in Minecraft, as evidenced by their samples. We then apply the models to the localization problem, investigating both generative and discriminative approaches, and compare the different ways in which they each capture task uncertainty. Our results show that models with implicit mapping are able to capture the underlying 3D structure of visually complex scenes, and use this to accurately localize new observations, paving the way towards future applications in sequential localization. Supplementary video available at https://youtu.be/iHEXX5wXbCI.