 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextTopicNet - Self-Supervised Learning of Visual Features Through Embedding Images on Semantic Text Spaces
Paper and Code
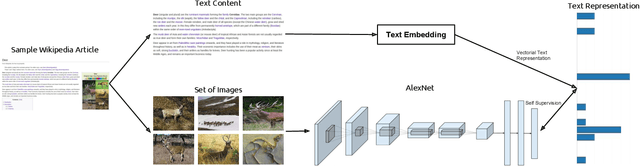
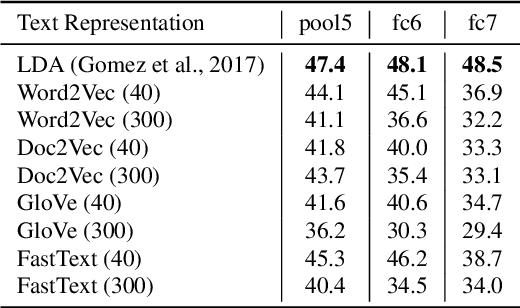

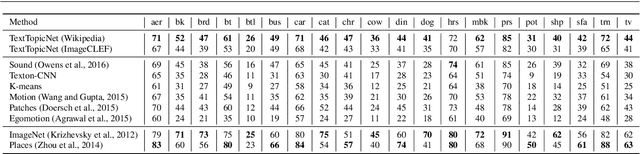
The immense success of deep learning based methods in computer vision heavily relies on large scale training datasets. These richly annotated datasets help the network learn discriminative visual features. Collecting and annotating such datasets requires a tremendous amount of human effort and annotations are limited to popular set of classes. As an alternative, learning visual features by designing auxiliary tasks which make use of freely available self-supervision has become increasingly popular in the computer vision community. In this paper, we put forward an idea to take advantage of multi-modal context to provide self-supervision for the training of computer vision algorithms. We show that adequate visual features can be learned efficiently by training a CNN to predict the semantic textual context in which a particular image is more probable to appear as an illustration. More specifically we use popular text embedding techniques to provide the self-supervision for the training of deep CNN. Our experiments demonstrate state-of-the-art performance in image classification, object detection, and multi-modal retrieval compared to recent self-supervised or naturally-supervised approaches.