 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning From Synthetic To Real Images Using Variational Autoencoders For Precise Position Detection
Paper and Code
Jul 04, 2018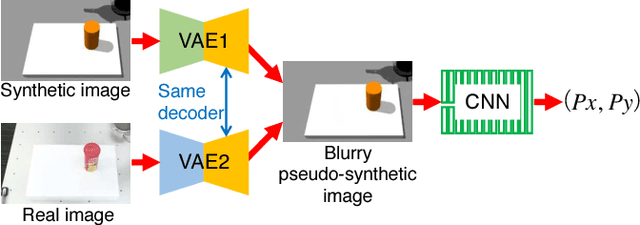
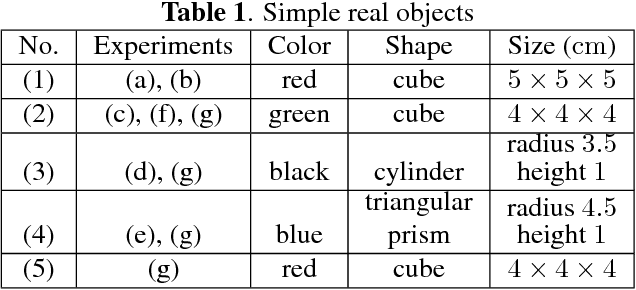
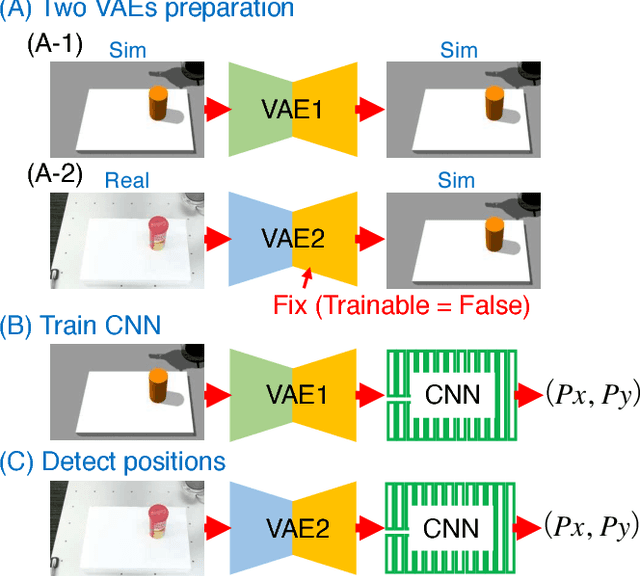

Capturing and labeling camera images in the real world is an expensive task, whereas synthesizing labeled images in a simulation environment is easy for collecting large-scale image data. However, learning from only synthetic images may not achieve the desired performance in the real world due to a gap between synthetic and real images. We propose a method that transfers learned detection of an object position from a simulation environment to the real world. This method uses only a significantly limited dataset of real images while leveraging a large dataset of synthetic images using variational autoencoders. Additionally, the proposed method consistently performed well in different lighting conditions, in the presence of other distractor objects, and on different backgrounds. Experimental results showed that it achieved accuracy of 1.5mm to 3.5mm on average. Furthermore, we showed how the method can be used in a real-world scenario like a "pick-and-place" robotic task.