 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Deep Recurrent Neural Networks for Basic Dance Step Generation
Paper and Code
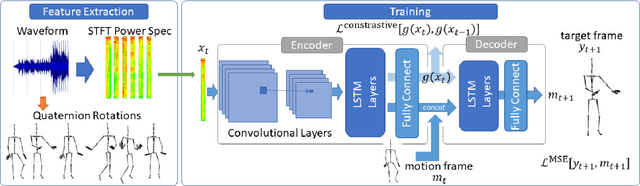
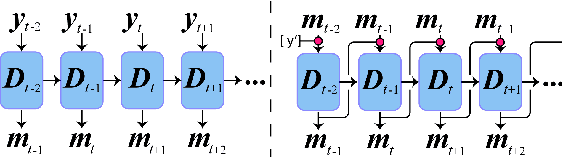
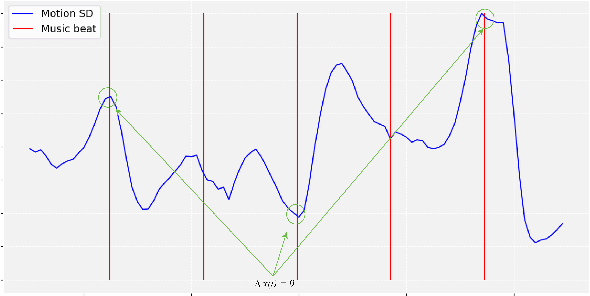
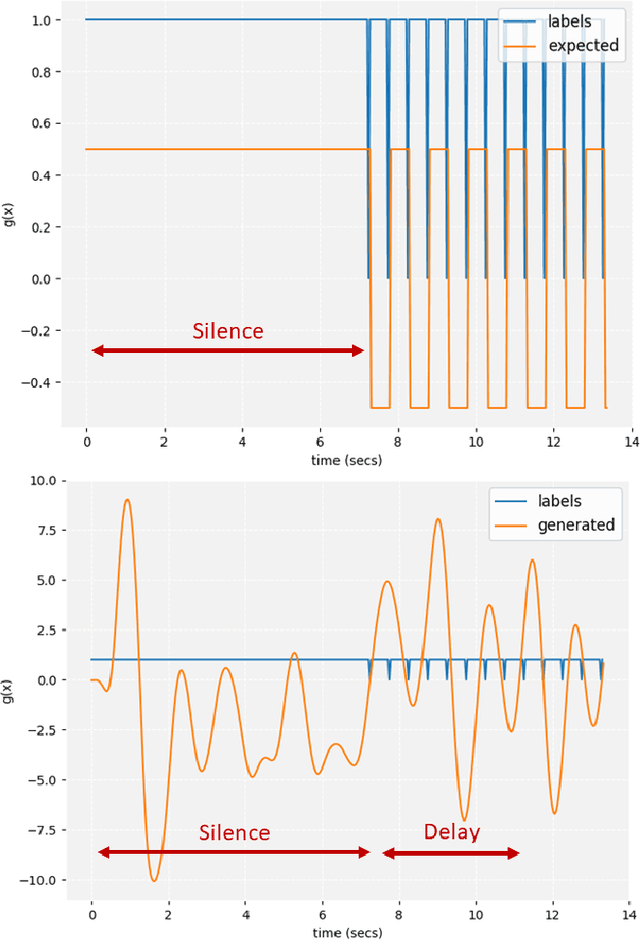
A deep recurrent neural network with audio input is applied to model basic dance steps. The proposed model employs multilayered Long Short-Term Memory (LSTM) layers and convolutional layers to process the audio power spectrum. Then, another deep LSTM layer decodes the target dance sequence. This end-to-end approach has an auto-conditioned decode configuration that reduces accumulation of feedback error. Experimental results demonstrate that, after training using a small dataset, the model generates basic dance steps with low cross entropy and maintains a motion beat F-measure score similar to that of a baseline dancer. In addition, we investigate the use of a contrastive cost function for music-motion regulation. This cost function targets motion direction and maps similarities between music frames. Experimental result demonstrate that the cost function improves the motion beat f-score.