 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCR-GAN: Learning Complete Representations for Multi-view Generation
Paper and Code
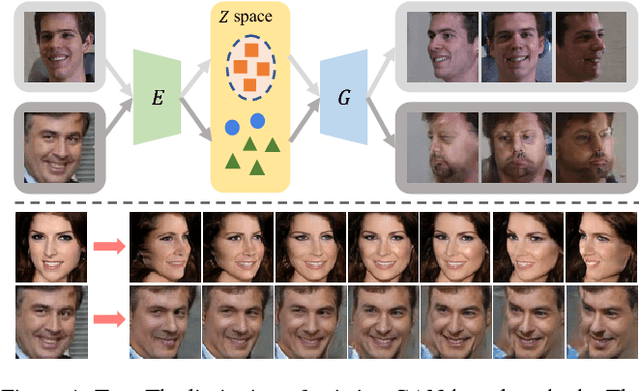
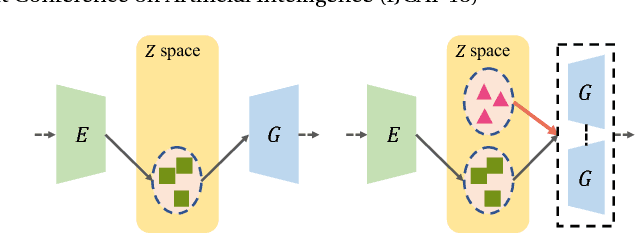
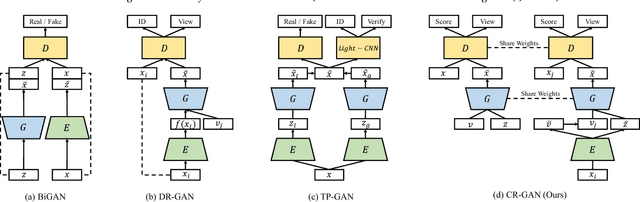

Generating multi-view images from a single-view input is an essential yet challenging problem. It has broad applications in vision, graphics, and robotics. Our study indicates that the widely-used generative adversarial network (GAN) may learn "incomplete" representations due to the single-pathway framework: an encoder-decoder network followed by a discriminator network. We propose CR-GAN to address this problem. In addition to the single reconstruction path, we introduce a generation sideway to maintain the completeness of the learned embedding space. The two learning pathways collaborate and compete in a parameter-sharing manner, yielding considerably improved generalization ability to "unseen" dataset. More importantly, the two-pathway framework makes it possible to combine both labeled and unlabeled data for self-supervised learning, which further enriches the embedding space for realistic generations. The experimental results prove that CR-GAN significantly outperforms state-of-the-art methods, especially when generating from "unseen" inputs in wild conditions.