 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sparse Recovery Autoencoder
Paper and Code
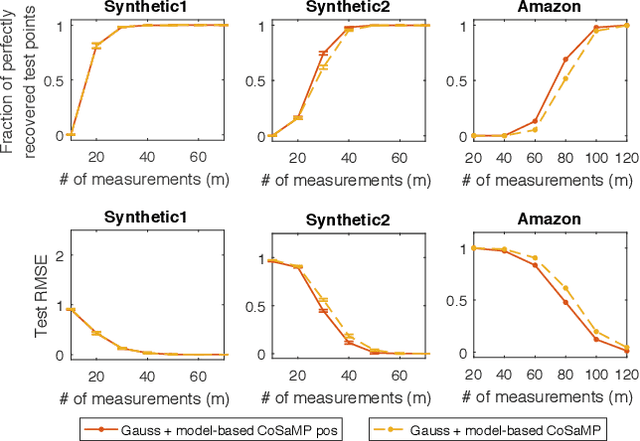
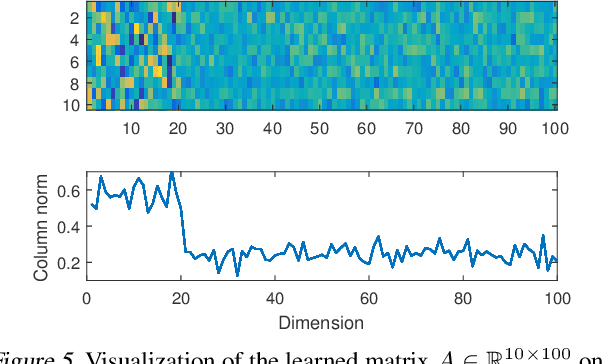
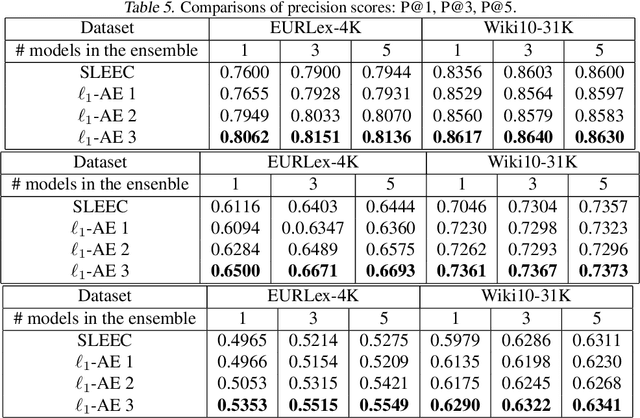
Linear encoding of sparse vectors is widely popular, but is most commonly data-independent -- missing any possible extra (but a-priori unknown) structure beyond sparsity. In this paper we present a new method to learn linear encoders that adapt to data, while still performing well with the widely used $\ell_1$ decoder. The convex $\ell_1$ decoder prevents gradient propagation as needed in standard autoencoder training. Our method is based on the insight that unfolding the convex decoder into $T$ projected gradient steps can address this issue. Our method can be seen as a data-driven way to learn a compressed sensing matrix. Our experiments show that there is indeed additional structure beyond sparsity in several real datasets. Our autoencoder is able to discover it and exploit it to create excellent reconstructions with fewer measurements compared to the previous state of the art methods.