 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Saddle Point Problem with Applications to Constrained Online Convex Optimization
Paper and Code
Jun 21, 2018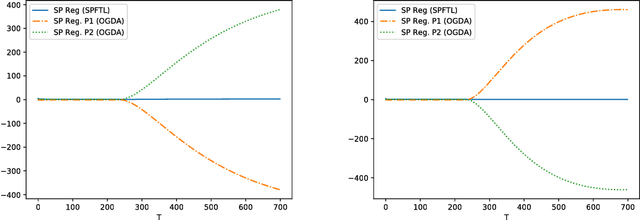
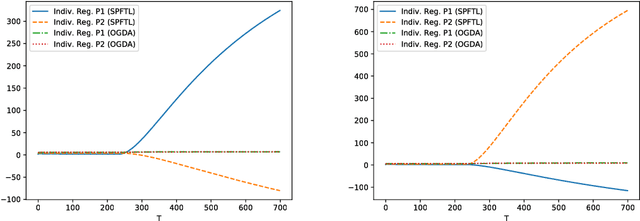
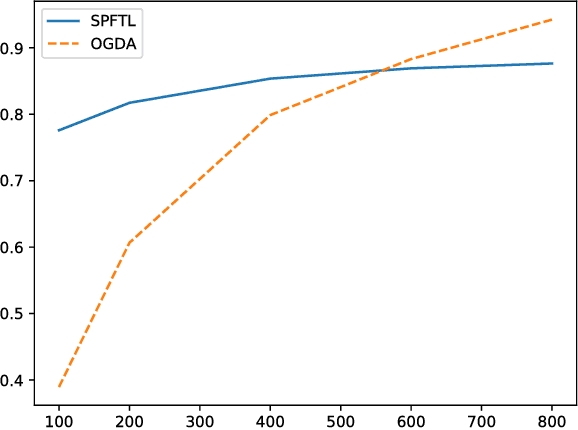
We study an online saddle point problem where at each iteration a pair of actions need to be chosen without knowledge of the future (convex-concave) payoff functions. The objective is to minimize the gap between the cumulative payoffs and the saddle point value of the aggregate payoff function, which we measure using a metric called "SP-regret". The problem generalizes the online convex optimization framework and can be interpreted as finding the Nash equilibrium for the aggregate of a sequence of two-player zero-sum games. We propose an algorithm that achieves $\tilde{O}(\sqrt{T})$ SP-regret in the general case, and $O(\log T)$ SP-regret for the strongly convex-concave case. We then consider a constrained online convex optimization problem motivated by a variety of applications in dynamic pricing, auctions, and crowdsourcing. We relate this problem to an online saddle point problem and establish $O(\sqrt{T})$ regret using a primal-dual algorithm.