Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dissection of Overfitting and Generalization in Continuous Reinforcement Learning
Paper and Code
Jun 25, 2018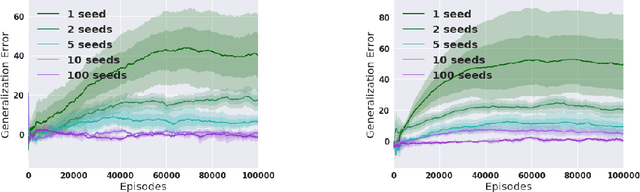
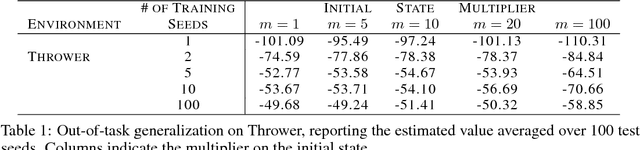
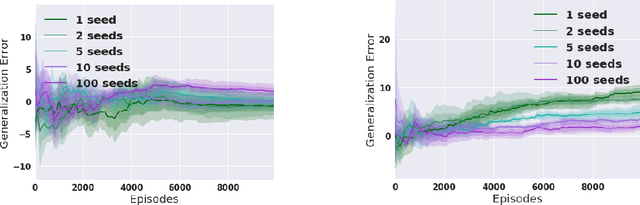

The risks and perils of overfitting in machine learning are well known. However most of the treatment of this, including diagnostic tools and remedies, was developed for the supervised learning case. In this work, we aim to offer new perspectives on the characterization and prevention of overfitting in deep Reinforcement Learning (RL) methods, with a particular focus on continuous domains. We examine several aspects, such as how to define and diagnose overfitting in MDPs, and how to reduce risks by injecting sufficient training diversity. This work complements recent findings on the brittleness of deep RL methods and offers practical observations for RL researchers and practitioners.
* 20 pages, 16 figures
View paper on