 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Visual Knowledge Memory Networks for Visual Question Answering
Paper and Code
Jun 13, 2018
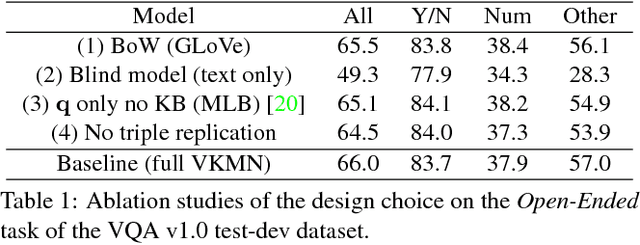
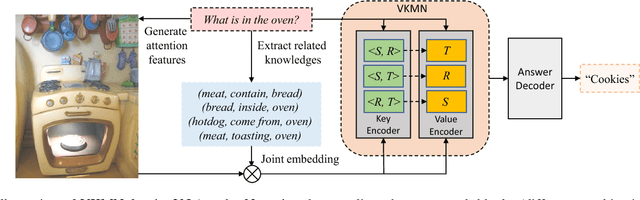
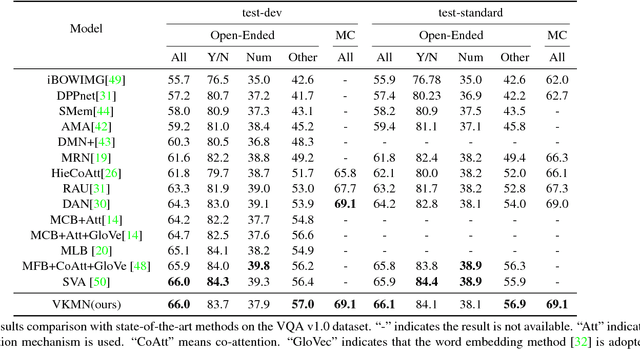
Visual question answering (VQA) requires joint comprehension of images and natural language questions, where many questions can't be directly or clearly answered from visual content but require reasoning from structured human knowledge with confirmation from visual content. This paper proposes visual knowledge memory network (VKMN) to address this issue, which seamlessly incorporates structured human knowledge and deep visual features into memory networks in an end-to-end learning framework. Comparing to existing methods for leveraging external knowledge for supporting VQA, this paper stresses more on two missing mechanisms. First is the mechanism for integrating visual contents with knowledge facts. VKMN handles this issue by embedding knowledge triples (subject, relation, target) and deep visual features jointly into the visual knowledge features. Second is the mechanism for handling multiple knowledge facts expanding from question and answer pairs. VKMN stores joint embedding using key-value pair structure in the memory networks so that it is easy to handle multiple facts. Experiments show that the proposed method achieves promising results on both VQA v1.0 and v2.0 benchmarks, while outperforms state-of-the-art methods on the knowledge-reasoning related questions.