 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Will Gradient Methods Converge to Max-margin Classifier under ReLU Models?
Paper and Code
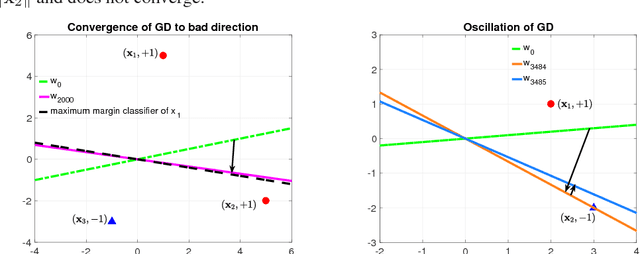
We study the implicit bias of gradient descent methods in solving a binary classification problem over a linearly separable dataset. The classifier is described by a nonlinear ReLU model and the objective function adopts the exponential loss function. We first characterize the landscape of the loss function and show that there can exist spurious asymptotic local minima besides asymptotic global minima. We then show that gradient descent (GD) can converge to either a global or a local max-margin direction, or may diverge from the desired max-margin direction in a general context. For stochastic gradient descent (SGD), we show that it converges in expectation to either the global or the local max-margin direction if SGD converges. We further explore the implicit bias of these algorithms in learning a multi-neuron network under certain stationary conditions, and show that the learned classifier maximizes the margins of each sample pattern partition under the ReLU activation.