 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponential convergence rates for Batch Normalization: The power of length-direction decoupling in non-convex optimization
Paper and Code
Oct 06, 2018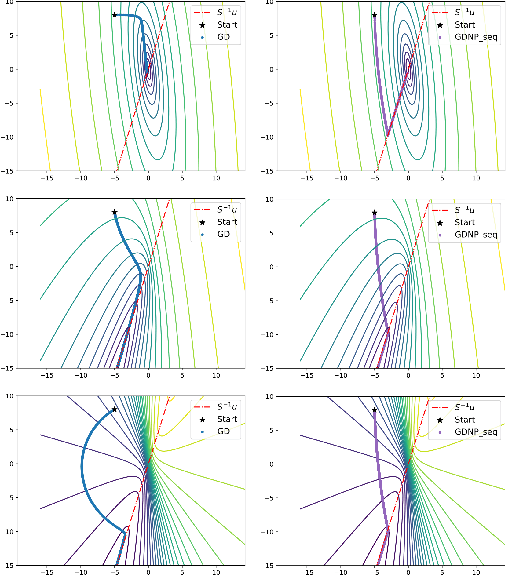

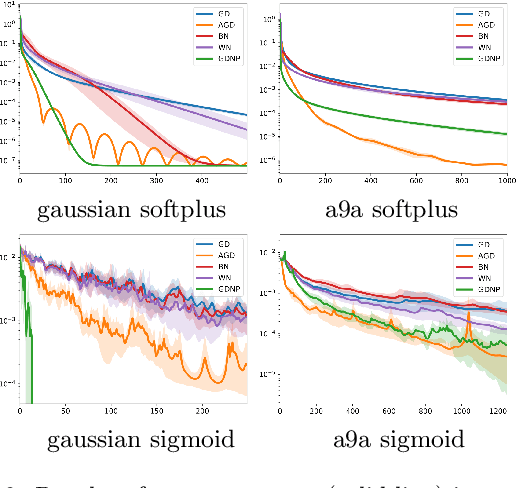
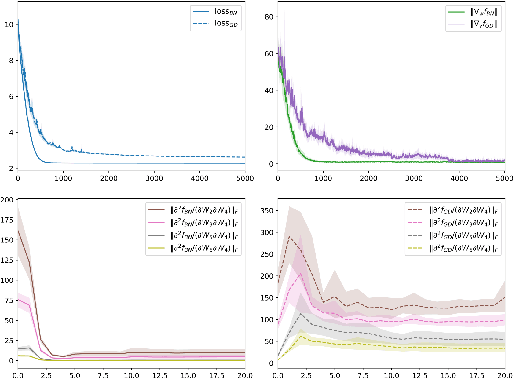
Normalization techniques such as Batch Normalization have been applied successfully for training deep neural networks. Yet, despite its apparent empirical benefits, the reasons behind the success of Batch Normalization are mostly hypothetical. We here aim to provide a more thorough theoretical understanding from a classical optimization perspective. Our main contribution towards this goal is the identification of various problem instances in the realm of machine learning where % -- under certain assumptions-- Batch Normalization can provably accelerate optimization. We argue that this acceleration is due to the fact that Batch Normalization splits the optimization task into optimizing length and direction of the parameters separately. This allows gradient-based methods to leverage a favourable global structure in the loss landscape that we prove to exist in Learning Halfspace problems and neural network training with Gaussian inputs. We thereby turn Batch Normalization from an effective practical heuristic into a provably converging algorithm for these settings. Furthermore, we substantiate our analysis with empirical evidence that suggests the validity of our theoretical results in a broader context.