 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Hierarchical Visual Representations in Deep Neural Networks Using Hierarchical Linguistic Labels
Paper and Code
May 19, 2018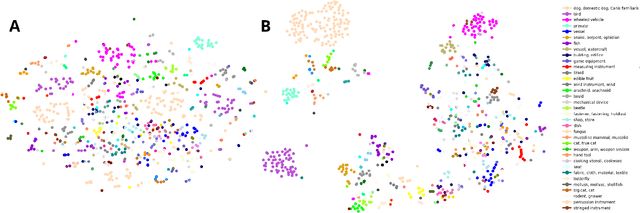
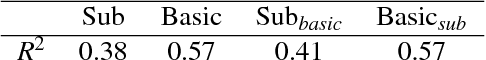
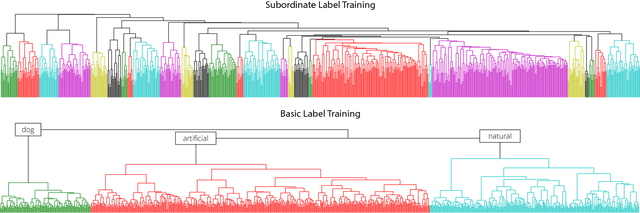

Modern convolutional neural networks (CNNs) are able to achieve human-level object classification accuracy on specific tasks, and currently outperform competing models in explaining complex human visual representations. However, the categorization problem is posed differently for these networks than for humans: the accuracy of these networks is evaluated by their ability to identify single labels assigned to each image. These labels often cut arbitrarily across natural psychological taxonomies (e.g., dogs are separated into breeds, but never jointly categorized as "dogs"), and bias the resulting representations. By contrast, it is common for children to hear both "dog" and "Dalmatian" to describe the same stimulus, helping to group perceptually disparate objects (e.g., breeds) into a common mental class. In this work, we train CNN classifiers with multiple labels for each image that correspond to different levels of abstraction, and use this framework to reproduce classic patterns that appear in human generalization behavior.