 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Parallel Backpropagation with Convergence Guarantee
Paper and Code
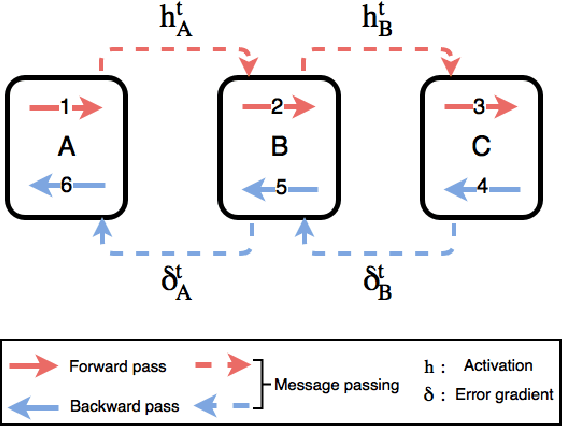
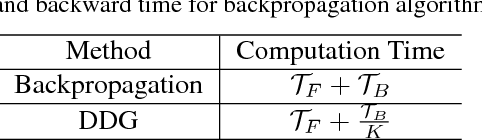
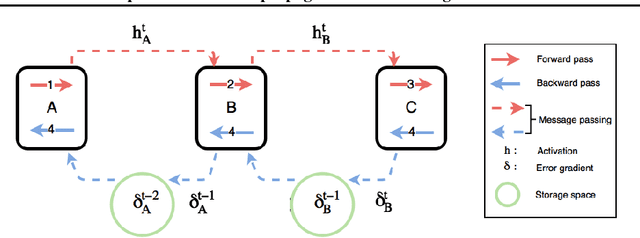
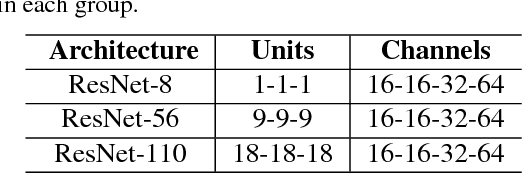
Backpropagation algorithm is indispensable for the training of feedforward neural networks. It requires propagating error gradients sequentially from the output layer all the way back to the input layer. The backward locking in backpropagation algorithm constrains us from updating network layers in parallel and fully leveraging the computing resources. Recently, several algorithms have been proposed for breaking the backward locking. However, their performances degrade seriously when networks are deep. In this paper, we propose decoupled parallel backpropagation algorithm for deep learning optimization with convergence guarantee. Firstly, we decouple the backpropagation algorithm using delayed gradients, and show that the backward locking is removed when we split the networks into multiple modules. Then, we utilize decoupled parallel backpropagation in two stochastic methods and prove that our method guarantees convergence to critical points for the non-convex problem. Finally, we perform experiments for training deep convolutional neural networks on benchmark datasets. The experimental results not only confirm our theoretical analysis, but also demonstrate that the proposed method can achieve significant speedup without loss of accuracy.