 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue-aware Quantization for Training and Inference of Neural Networks
Paper and Code
Apr 20, 2018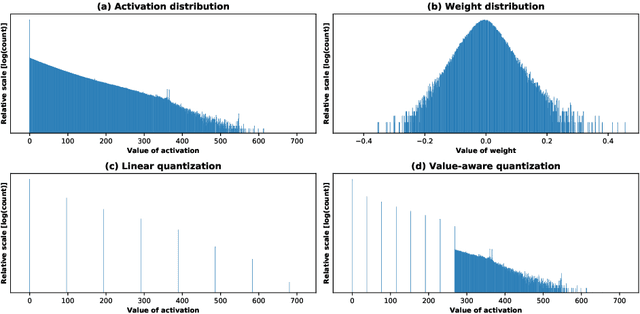
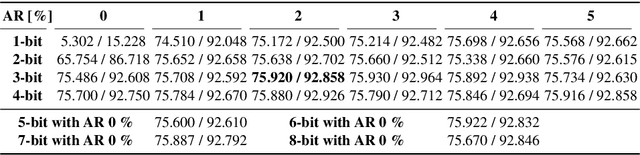
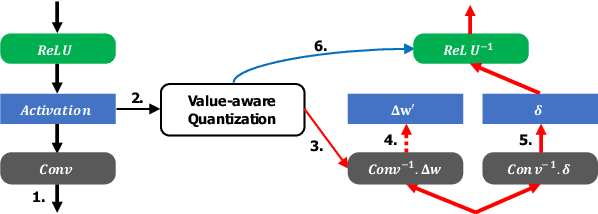

We propose a novel value-aware quantization which applies aggressively reduced precision to the majority of data while separately handling a small amount of large data in high precision, which reduces total quantization errors under very low precision. We present new techniques to apply the proposed quantization to training and inference. The experiments show that our method with 3-bit activations (with 2% of large ones) can give the same training accuracy as full-precision one while offering significant (41.6% and 53.7%) reductions in the memory cost of activations in ResNet-152 and Inception-v3 compared with the state-of-the-art method. Our experiments also show that deep networks such as Inception-v3, ResNet-101 and DenseNet-121 can be quantized for inference with 4-bit weights and activations (with 1% 16-bit data) within 1% top-1 accuracy drop.