 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA comparison of recent waveform generation and acoustic modeling methods for neural-network-based speech synthesis
Paper and Code
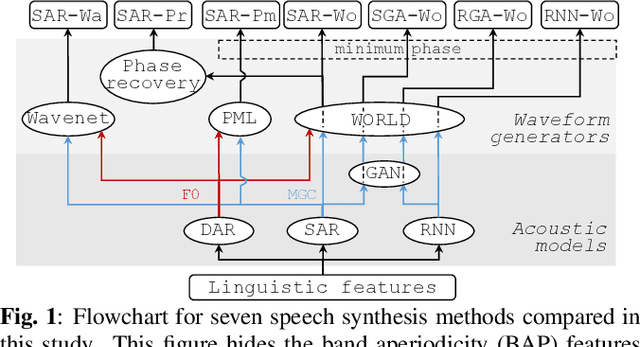
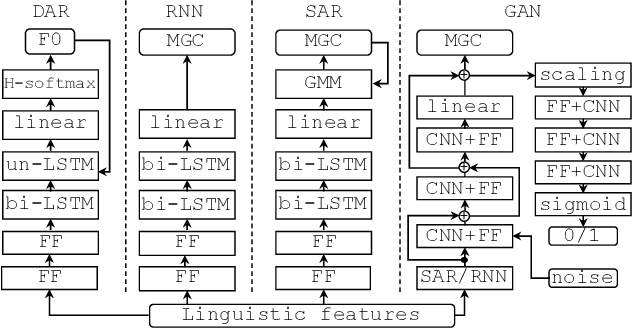
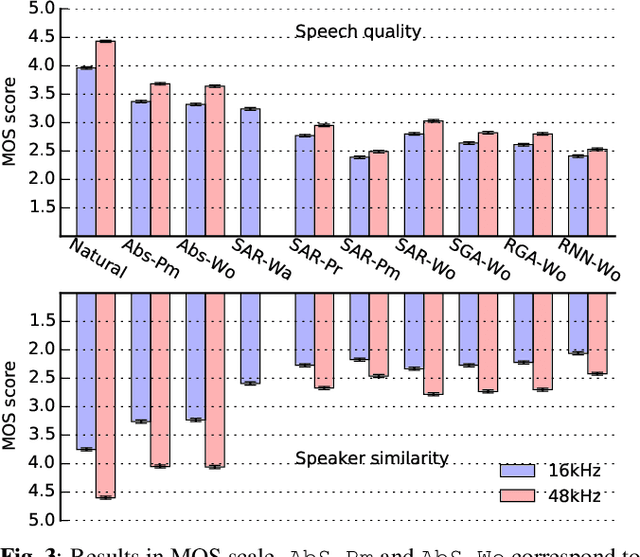
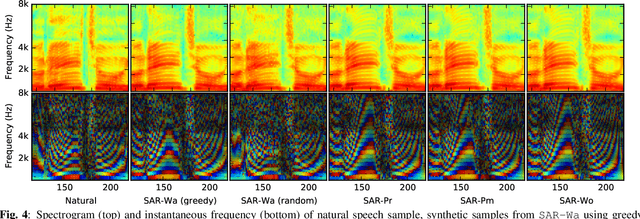
Recent advances in speech synthesis suggest that limitations such as the lossy nature of the amplitude spectrum with minimum phase approximation and the over-smoothing effect in acoustic modeling can be overcome by using advanced machine learning approaches. In this paper, we build a framework in which we can fairly compare new vocoding and acoustic modeling techniques with conventional approaches by means of a large scale crowdsourced evaluation. Results on acoustic models showed that generative adversarial networks and an autoregressive (AR) model performed better than a normal recurrent network and the AR model performed best. Evaluation on vocoders by using the same AR acoustic model demonstrated that a Wavenet vocoder outperformed classical source-filter-based vocoders. Particularly, generated speech waveforms from the combination of AR acoustic model and Wavenet vocoder achieved a similar score of speech quality to vocoded speech.