 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Ramp Merge Maneuver Based on Reinforcement Learning with Continuous Action Space
Paper and Code
Mar 25, 2018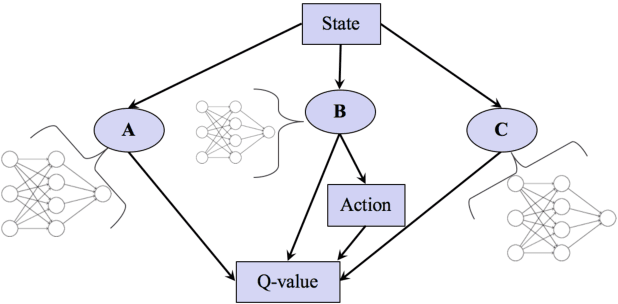

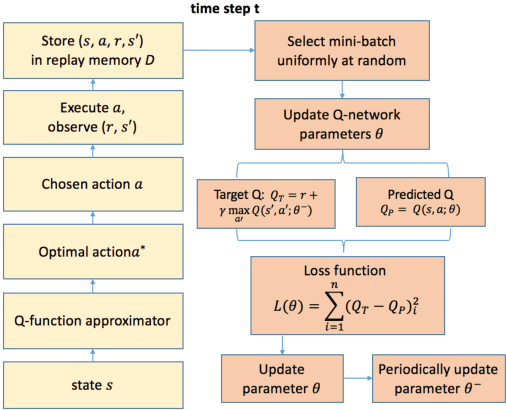
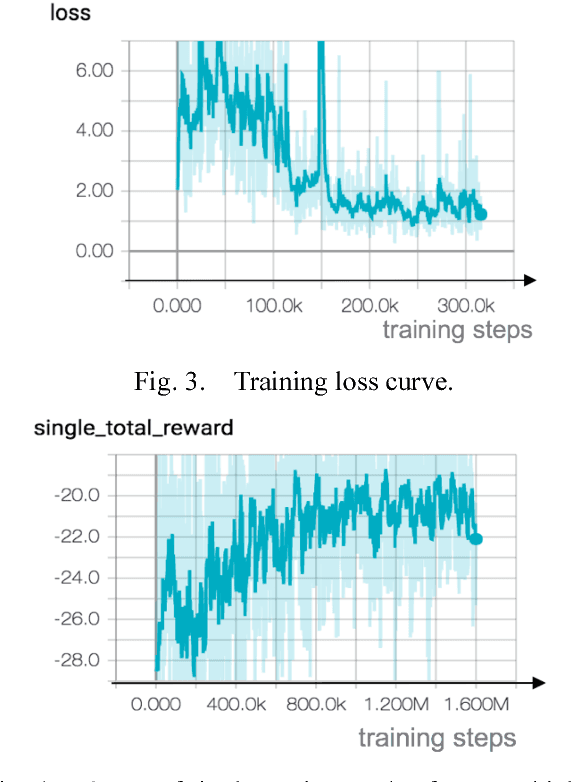
Ramp merging is a critical maneuver for road safety and traffic efficiency. Most of the current automated driving systems developed by multiple automobile manufacturers and suppliers are typically limited to restricted access freeways only. Extending the automated mode to ramp merging zones presents substantial challenges. One is that the automated vehicle needs to incorporate a future objective (e.g. a successful and smooth merge) and optimize a long-term reward that is impacted by subsequent actions when executing the current action. Furthermore, the merging process involves interaction between the merging vehicle and its surrounding vehicles whose behavior may be cooperative or adversarial, leading to distinct merging countermeasures that are crucial to successfully complete the merge. In place of the conventional rule-based approaches, we propose to apply reinforcement learning algorithm on the automated vehicle agent to find an optimal driving policy by maximizing the long-term reward in an interactive driving environment. Most importantly, in contrast to most reinforcement learning applications in which the action space is resolved as discrete, our approach treats the action space as well as the state space as continuous without incurring additional computational costs. Our unique contribution is the design of the Q-function approximation whose format is structured as a quadratic function, by which simple but effective neural networks are used to estimate its coefficients. The results obtained through the implementation of our training platform demonstrate that the vehicle agent is able to learn a safe, smooth and timely merging policy, indicating the effectiveness and practicality of our approach.