 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset and Architecture for Visual Reasoning with a Working Memory
Paper and Code
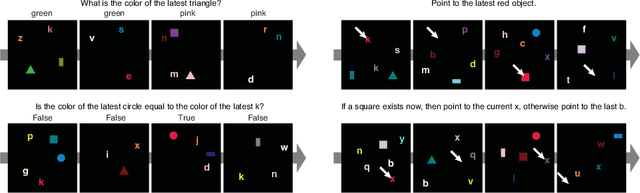
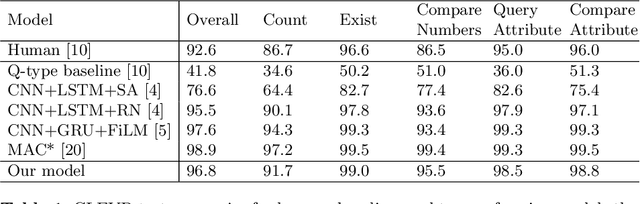
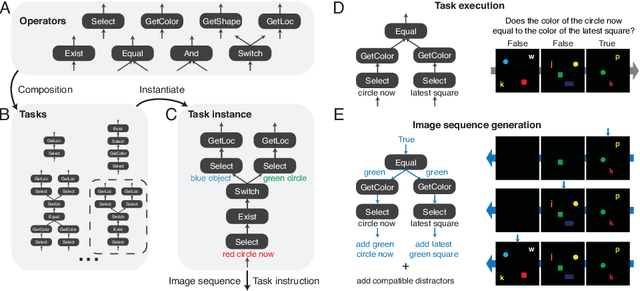
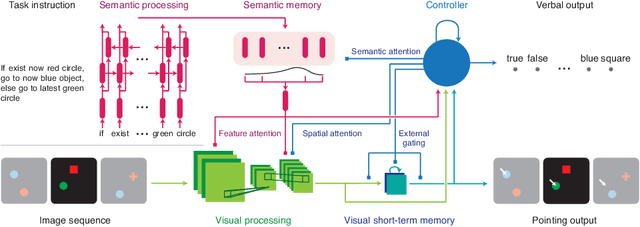
A vexing problem in artificial intelligence is reasoning about events that occur in complex, changing visual stimuli such as in video analysis or game play. Inspired by a rich tradition of visual reasoning and memory in cognitive psychology and neuroscience, we developed an artificial, configurable visual question and answer dataset (COG) to parallel experiments in humans and animals. COG is much simpler than the general problem of video analysis, yet it addresses many of the problems relating to visual and logical reasoning and memory -- problems that remain challenging for modern deep learning architectures. We additionally propose a deep learning architecture that performs competitively on other diagnostic VQA datasets (i.e. CLEVR) as well as easy settings of the COG dataset. However, several settings of COG result in datasets that are progressively more challenging to learn. After training, the network can zero-shot generalize to many new tasks. Preliminary analyses of the network architectures trained on COG demonstrate that the network accomplishes the task in a manner interpretable to humans.