 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lottery Ticket Hypothesis: Finding Small, Trainable Neural Networks
Paper and Code

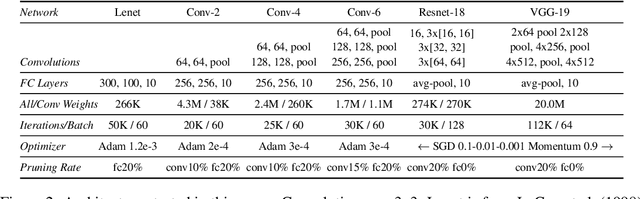
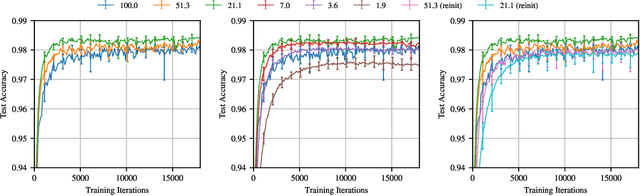
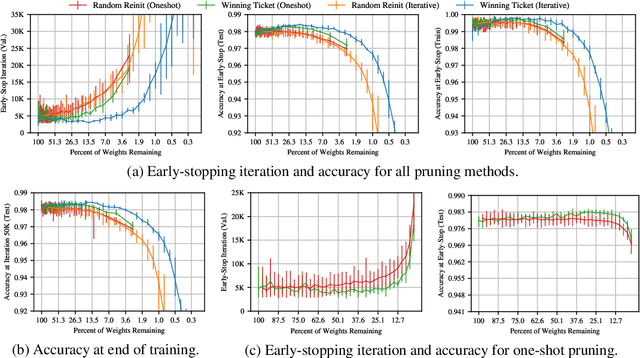
Neural network compression techniques are able to reduce the parameter counts of trained networks by over 90%--decreasing storage requirements and improving inference performance--without compromising accuracy. However, contemporary experience is that it is difficult to train small architectures from scratch, which would similarly improve training performance. We articulate a new conjecture to explain why it is easier to train large networks: the "lottery ticket hypothesis." It states that large networks that train successfully contain subnetworks that--when trained in isolation--converge in a comparable number of iterations to comparable accuracy. These subnetworks, which we term "winning tickets," have won the initialization lottery: their connections have initial weights that make training particularly effective. We find that a standard technique for pruning unnecessary network weights naturally uncovers a subnetwork which, at the start of training, comprised a winning ticket. We present an algorithm to identify winning tickets and a series of experiments that support the lottery ticket hypothesis. We consistently find winning tickets that are less than 20% of the size of several fully-connected, convolutional, and residual architectures for MNIST and CIFAR10. Furthermore, winning tickets at moderate levels of pruning (20-50% of the original network size) converge up to 6.7x faster than the original network and exhibit higher test accuracy.