 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Network Compression with Single and Multiple Level Quantization
Paper and Code
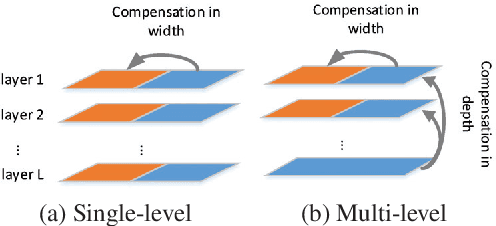

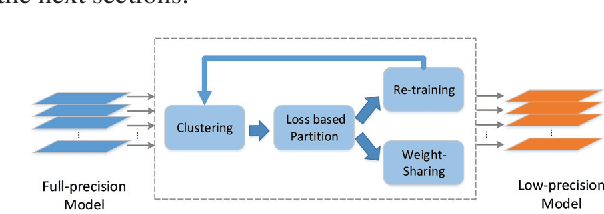

Network quantization is an effective solution to compress deep neural networks for practical usage. Existing network quantization methods cannot sufficiently exploit the depth information to generate low-bit compressed network. In this paper, we propose two novel network quantization approaches, single-level network quantization (SLQ) for high-bit quantization and multi-level network quantization (MLQ) for extremely low-bit quantization (ternary).We are the first to consider the network quantization from both width and depth level. In the width level, parameters are divided into two parts: one for quantization and the other for re-training to eliminate the quantization loss. SLQ leverages the distribution of the parameters to improve the width level. In the depth level, we introduce incremental layer compensation to quantize layers iteratively which decreases the quantization loss in each iteration. The proposed approaches are validated with extensive experiments based on the state-of-the-art neural networks including AlexNet, VGG-16, GoogleNet and ResNet-18. Both SLQ and MLQ achieve impressive results.