 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning to Rank in E-Commerce Search Engine: Formalization, Analysis, and Application
Paper and Code
May 23, 2018
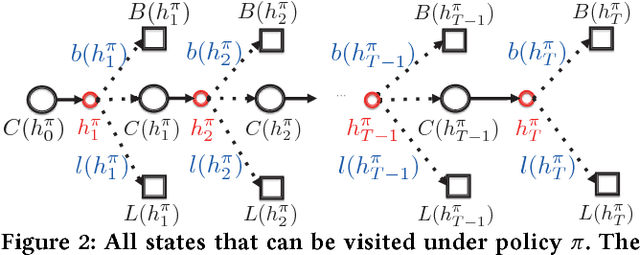
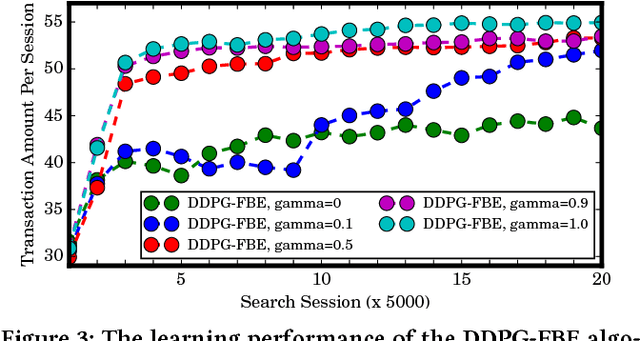
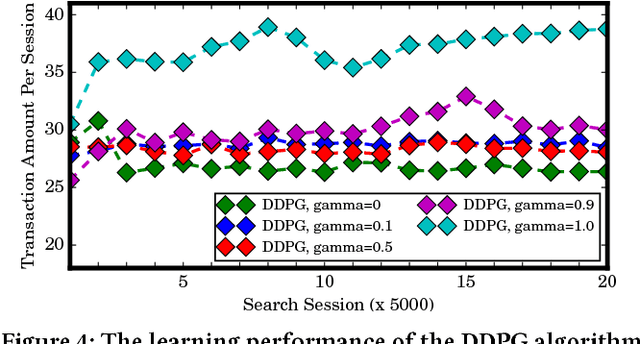
In e-commerce platforms such as Amazon and TaoBao, ranking items in a search session is a typical multi-step decision-making problem. Learning to rank (LTR) methods have been widely applied to ranking problems. However, such methods often consider different ranking steps in a session to be independent, which conversely may be highly correlated to each other. For better utilizing the correlation between different ranking steps, in this paper, we propose to use reinforcement learning (RL) to learn an optimal ranking policy which maximizes the expected accumulative rewards in a search session. Firstly, we formally define the concept of search session Markov decision process (SSMDP) to formulate the multi-step ranking problem. Secondly, we analyze the property of SSMDP and theoretically prove the necessity of maximizing accumulative rewards. Lastly, we propose a novel policy gradient algorithm for learning an optimal ranking policy, which is able to deal with the problem of high reward variance and unbalanced reward distribution of an SSMDP. Experiments are conducted in simulation and TaoBao search engine. The results demonstrate that our algorithm performs much better than online LTR methods, with more than 40% and 30% growth of total transaction amount in the simulation and the real application, respectively.